Introduction: The Planetary Science Archive (PSA)[1] of the European Space Agency (ESA) has, over the past year, incorporated new interfaces for accessing the data. These new interfaces (an improved SFTP[2], the PSA PDS[3] API[4] and ESA Datalabs[5]), along with enhancements to the existing ones (TAP/EPN-TAP[6] and UI[7]), have considerably contributed to expand the interoperability mechanisms of the archive.
Here we describe various use cases (for both PDS3[8] and PDS4[9] data formats) in which all or part of these interfaces are used, showing different ways to obtain results from the same source archive.
Example Overview: The use case will simply be to access some PDS3 and PDS4 products by their logical identifier. These are the missions and instruments we will use for this (both Martian missions).
|
Mission
|
Format
|
Instr.
|
Product identifier
|
|
Mars Express
|
PDS3
|
HRSC
|
MEX-M-HRSC-3-RDR-EXT9-V4.0:DATA:HO799_0000_S23.IMG
|
|
ExoMars TGO
|
PDS4
|
ACS
|
urn:esa:psa:em16_tgo_acs:data_raw:acs_raw_hk_nir_20180613t180000-20180613t235959::1.0
|
Depending on the interface, the result will be either the download of the data product or the associated metadata (bundles/datasets, collections, label files, etc.)
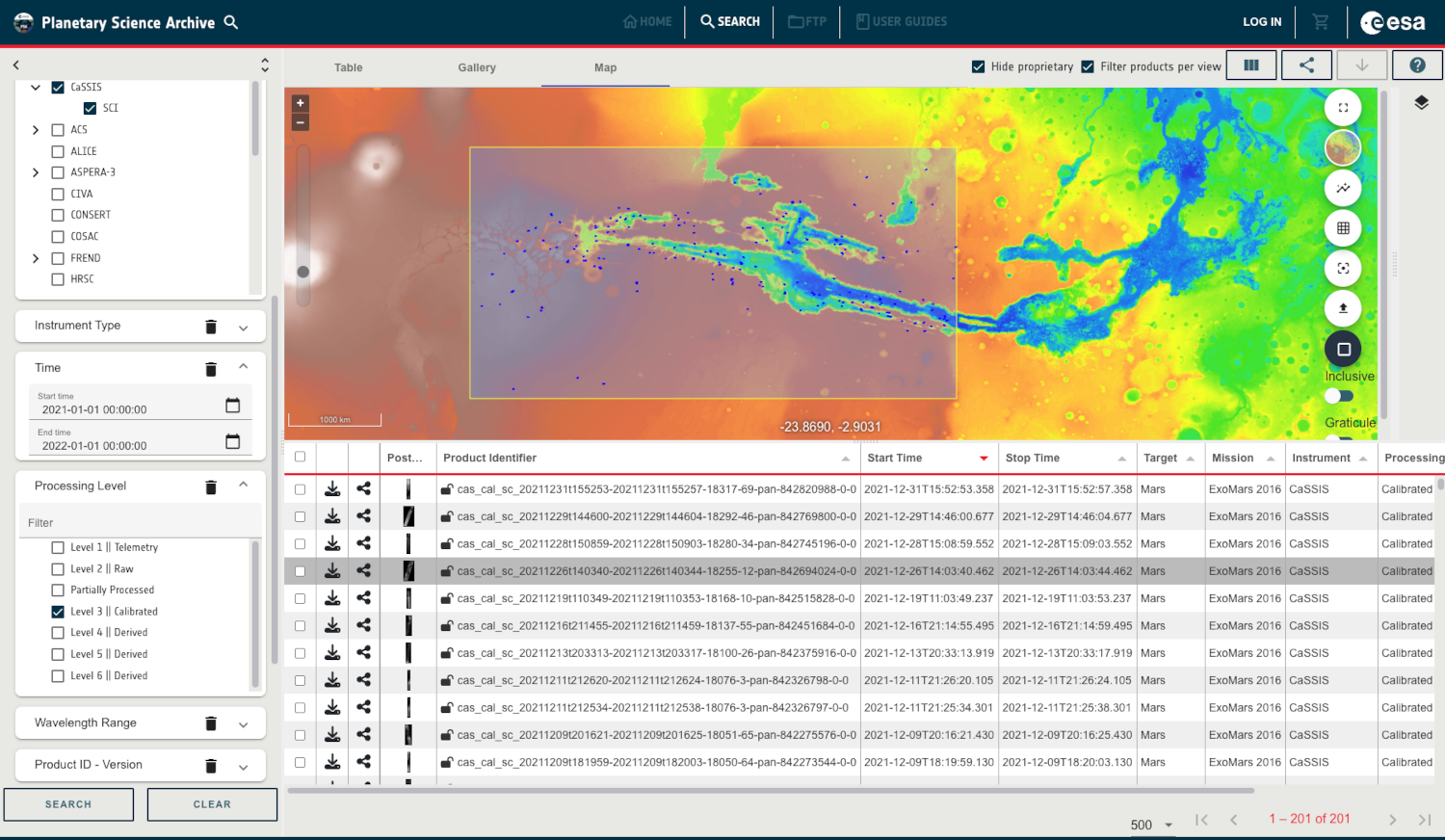
GUI: The PSA Graphical User Interface (PSA GUI), which has been recently refurbished using the Angular framework, offering a modern and responsive design, allows the user to visualize data in a friendly way and search for PDS3 or PDS4 products via a rich set of filters. For our use case, we will use the Product ID field to search by the logical_identifier parameter (last version will be given by default).
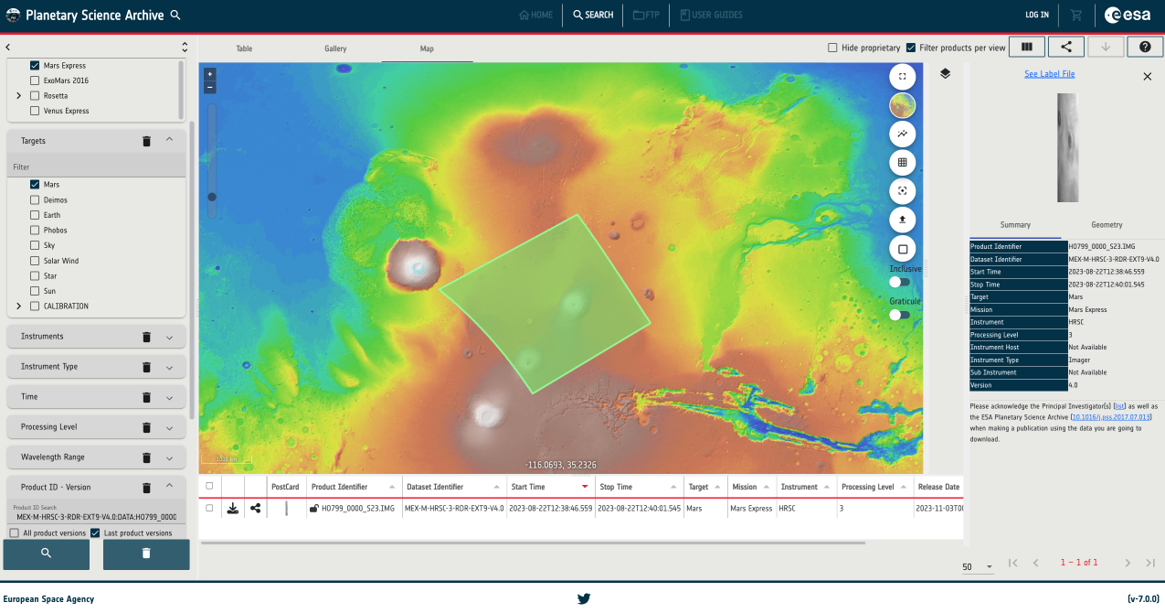
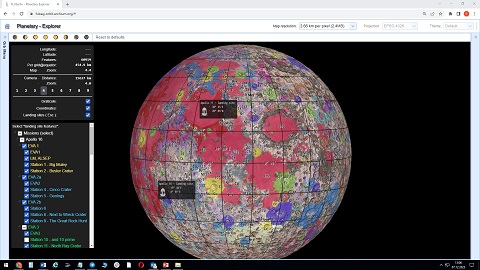
Figure 1: Getting a PDS3/4 product in the PSA GUI and displaying it in the Mars map view.
TAP/EPN-TAP: The Table Access Protocol (TAP) service, running as a web application, allows searching PDS3 or PDS4 data by means of ADQL[10] queries. This service is used as back-end for the GUI shown before; in addition, it can be accessed directly through a browser, programmatically (with Bash, Python, etc.) or from a client application such as Topcat. For the PDS3 use case, we will use the EPN-TAP service (Europlanet extension based on TAP) via the curl command:
|
$ curl -X 'GET' \
'https://psa.esa.int/psa-tap/tap/sync?LANG=ADQL&REQUEST=doQuery&FORMAT=json&QUERY=select%20*%20from%20%20psa.epn_core%20where%20(obs_id=%27MEX-M-HRSC-3-RDR-EXT9-V4.0%3ADATA%3AHO799_0000_S23.IMG%27)' \
-H 'accept: *'
|
This returns a JSON file with expected metadata such as mission, instrument, bundle, collection, target, geometrical information, processing level, download path, etc.
SFTP: The new SFTP service, based on CrushFTP[11], provides a rich web client to download data, as well as a standard SFTP access. It uses a virtual volume behind the scenes, to get the available public/private data using the FUSE[12] technology. In this interface, the user may explore the structure of missions, datasets/bundles up to the desired level. For the use case, we will run the URL in the browser to get the same PDS3 product as before: https://psaftp.esac.esa.int/#/MARS-EXPRESS/HRSC/MEX-M-HRSC-3-RDR-EXT9-V4.0/DATA/O799/HO799_0000_S23.IMG
This will result in the download of the selected product to the user’s machine.
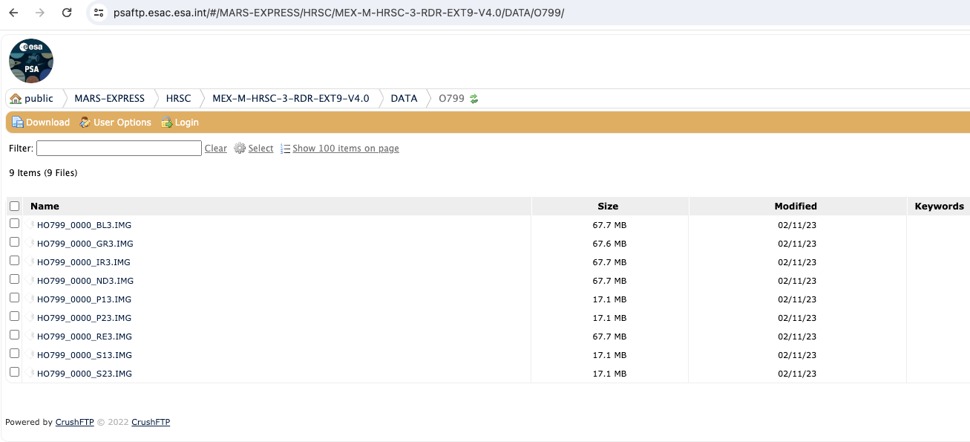
Figure 2: Accessing a PDS3/4 product and browsing its contents with the PSA new SFTP.
PDS API: The PDS API implemented by NASA makes use of the PDS4 harvester to access PDS4 data of the PSA (although PDS3 data is not yet available in PDS, the PDS3 to PDS4 migration activity of the PSA coming up soon will cover the retrieval of these datasets). The API can be accessed from a browser (Swagger[13]), command line, Jupyter notebook[14], etc. This API allows the user to search for PDS4 products and their references by their lidvid (logical identifier and version id), collections, specifying the returned fields and filtering by any of the metadata contained in their label files. This ability to query arbitrary meta-data makes it very powerful.
To get the example PDS4 product via the PDS API we would just use the following URL:
https://pds.nasa.gov/api/search/1/products/urn:esa:psa:em16_tgo_acs:data_raw:acs_raw_hk_nir_20180613t180000-20180613t235959::1.0
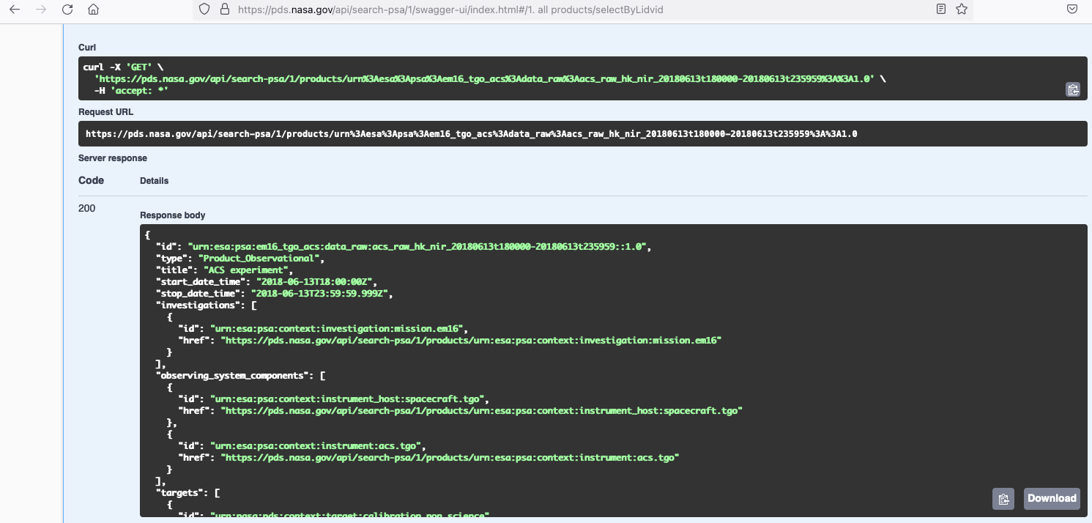
Figure 3: Getting metadata of a PDS4 product through the PSA PDS API (via Swagger API).
The response body includes product’s information such as the mission, instrument, observation dates, targets, etc. It also includes the PSA label (XML file) URL, which links to our PSA FTP repository.
Various response formats are supported, including CSV, XML, JSON and the original PDS4 label.
ESA Datalabs: Finally, this new framework allows the user to work with planetary data without needing to download it. In the example, a Jupyter Notebook is used to access and display the MEX HRSC product. For reading PDS3 data, the PDR[14] Python library is used.
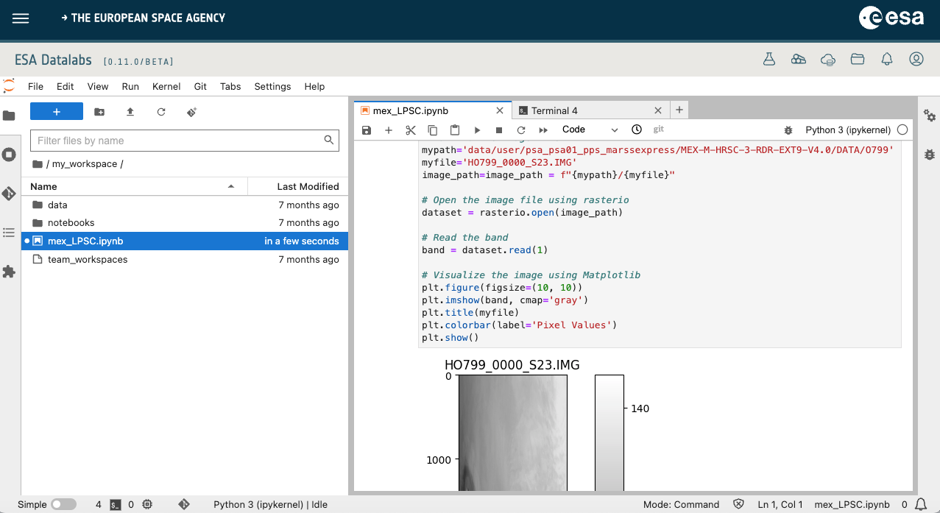
Figure 4: Getting and plotting a PDS3 product with ESA Datalabs.
Acknowledgments: We are grateful to the PSA development team for their invaluable assistance in creating and refining the PSA software. We also thank our advisors and supporters for their guidance and encouragement throughout the process.
References:
[1] S. Besse et al. (2018), ESA's Planetary Science Archive: Preserve and present reliable scientific data sets, Planetary and Space Science, Volume 150, p. 131-140.
[2] Secured FTP: https://psaftp.esac.esa.int/
[3] Planetary Data System: https://pds.nasa.gov/
[4] PDS PSA: https://pds.nasa.gov/api/search-psa/1/
[5] ESA Datalabs: https://datalabs.esa.int/
[6] TAP/EPN-TAP: https://psa.esa.int/psa-tap/tap/
[7] PSA User Interface: https://psa.esa.int
[8] PDS3 Archiving Guide:
https://www.cosmos.esa.int/documents/772136/977578/ESDC-PSA-TN-0008.pdf
[9] PDS4 Archiving Guide:
https://www.cosmos.esa.int/documents/772136/977578/ESDC-PSA-TN-0002+Iss2Rel5-5.pdf
[10] Astronomy Data Query Language (ADQL): https://www.ivoa.net/documents/ADQL/20180112/PR-ADQL-2.1-20180112.html
[11] CrushFTP: https://www.crushftp.com/index.html
[12] FUSE: https://github.com/libfuse/
[13] Swagger: https://swagger.io/
[14] Jupyter Notebook: https://jupyter.org/
[15] PDR python library: https://github.com/millionconcepts/pdr
![Fig. 1: Menu view of Planet Explorer test case showing the nearside of the Moon's surface [9].](data:image/jpeg;base64, /9j/4AAQSkZJRgABAQEAYABgAAD/4QAiRXhpZgAATU0AKgAAAAgAAQESAAMAAAABAAEAAAAAAAD/2wBDAAIBAQIBAQICAgICAgICAwUDAwMDAwYEBAMFBwYHBwcGBwcICQsJCAgKCAcHCg0KCgsMDAwMBwkODw0MDgsMDAz/2wBDAQICAgMDAwYDAwYMCAcIDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAz/wAARCAEOAeADASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwD9wNMl1LTvg9HPotv5upeaJFjUKDMouBvGWBHMe4ZwSOMA4ArU8T3Xi6LXW/si30WTTZLRRGbjf50dzvYsXwwHleWoUbct5jjPygkReM/iNeeEfHXhnQ7PwzqmrQa8ZxNfW8kEVvpyxBOG8x1LSNv3BF5McM7DJQI+z4h8QTaHNZLHp9zerdXCQu0TIPJDHG7BIJx9446KrHsAT7Vx393lOd8N6n8QLm5sf7U0vwzbwYKXnk3crSZDR4eMbSMFTJ8hJwQvzEck1LUPiHa6/efZdN8J3mmvsazR7yaCWICJDIsj7GDFpd6qVQBUAY5PyGP4rfFrUPh94k0LTrHQ4tUbWpViDy3b2/JnhjKx7YZA7qkrysrFP3cLsCQrlJvjj8Srr4WeA9V1q30fWtebSrQ3Q07R7Rrq/viDjy4YkBZm74UE4zwelOwijd678SYUPk6H4fuGlhj2FrholgmaacMH+Zi0axC2JK/MCZCFfhF3PDOpeLLrxE0eraXo9npfkeYs0F48sxl3EeWUKgYxht+fbBzkcd4r+N+oeFtLsbseG/GWpLfWP2vyrHTmnngkOwi3kjXlJNrOSWwqmPGSSBVDTv2nodUuL6CLQfiCt1p43PbSeHpo7iRTOYQ6o2DsJDOHOFZFYqSQRT5SeY9mrhfEY1648D+IG1+30lGh1E/2YbFnfNn5iCNpdwG2YgvuC5UDoetclZ/tJ3csdxJceDviRZx26O3OgySvIRIiKqLHuLFlk35GQBHJkjaCzrj9ou6hcef4N+I628kLPuXQmmbcokLRlIyxByiqCflYyKQdoYg5bO4ORx+n3/iB/iHqUNzY6PH4VjsLZrC7jvna9mui8vnpJCYwqoF8rBEh6Z+bewi2/MX+8v51pan8e4dFtGmvPCXja1jhhknuHk0VBFaqnJ3y7/L5X5gVdhjgkMCo3PBfjiTxmk839i6hplmqQy2txewxIt8kibwyKCXXaNoYOqkFsDOCa29oZ8pyPmL/AHl/OjzF/vL+deleZ7Q/9+1/wo8z2h/79r/hRzhynmvmL/eX86PMX+8v516V5ntD/wB+1/wo8z2h/wC/a/4Uc4cp5r5i/wB5fzo8xf7y/nXpXme0P/ftf8KPM9of+/a/4Uc4cp5r5i/3l/OjzF/vL+deleZ7Q/8Aftf8KPM9of8Av2v+FHOHKea+Yv8AeX86PMX+8v516V5ntD/37X/CjzPaH/v2v+FHOHKea+Yv95fzo8xf7y/nXpXme0P/AH7X/CjzPaH/AL9r/hRzhynmvmL/AHl/OjzF/vL+deleZ7Q/9+1/wo8z2h/79r/hRzhynmvmL/eX86PMX+8v516V5ntD/wB+1/wo8z2h/wC/a/4Uc4cp5r5i/wB5fzo8xf7y/nXpXme0P/ftf8KPM9of+/a/4Uc4cp5r5i/3l/OjzF/vL+deleZ7Q/8Aftf8KPM9of8Av2v+FHOHKea+Yv8AeX86PMX+8v516V5ntD/37X/CjzPaH/v2v+FHOHKea+Yv95fzo8xf7y/nXpXme0P/AH7X/CjzPaH/AL9r/hRzhynmvmL/AHl/OjzF/vL+deleZ7Q/9+1/wo8z2h/79r/hRzhynmvmL/eX86PMX+8v516V5ntD/wB+1/wo8z2h/wC/a/4Uc4cp5r5i/wB5fzo8xf7y/nXpXme0P/ftf8KPM9of+/a/4Uc4cp5r5i/3l/OjzF/vL+deleZ7Q/8Aftf8KPM9of8Av2v+FHOHKea+Yv8AeX86PMX+8v516V5ntD/37X/CjzPaH/v2v+FHOHKea+Yv95fzo8xf7y/nXpXme0P/AH7X/CjzPaH/AL9r/hRzhynmvmL/AHl/OjzF/vL+deleZ7Q/9+1/wo8z2h/79r/hRzhynmvmL/eX86PMX+8v516V5ntD/wB+1/wo8z2h/wC/a/4Uc4cp5r5i/wB5fzo8xf7y/nXpXme0P/ftf8Kp+IdWm0fQL67trIahcWsDyxWsaANcMqkhAQpPJGOFY+iscAnOHKcD5i/3l/OjzF/vL+ddVovxE+2fD6PXtQ0y50tlyLmzeANNbMspibIZUJAI3ZKrlecdqNP+ILXPw/vPEEmkzbbOK5nFpa+TcTXKQl8CM5VWdguACQu7IDMu2Rj2gcpx+pNM9hKLSWCO625iMoLR7hyAwBBwehwc4PHNOsjJFZwrcTRzTqiiWRE8tZGwNzBcnaCcnGTjOMnrXpHwi8Tt4+8NQXl5osmlzyCRZLa5iAkheORo2xwGKFlJUuqOVKlkQkoOb+APx7k+NfxA+IOh3ngDWvC8XgrVTYWeoX8H+i+IId8sf2i3YovHmQSAqNwA2HcdxAXtPIfIctALtdTuHkurN7FgvkQpbss0ZwNxaQyFXBOcAIuAQMnGTzvxp0jxZ4j+H93Z+CdctfDviCXPkahMsciwEI5T5ZIJ0ZTL5QdTHlo/MCtG5WRfXfhJ8b9A+Lni/wASaTZ2tmraLcBLd1lhl+2weVExm2oxaPEkjJhwpypH3lkRML4M/tDyfFT4teKPDU3hPT7W38O6Vbait9ZX5vBNLNdX0DWcitBGsVxGtpHI6b2IFygOBhmXtfIfszMmljaVinyoWO0HsO1YvhS21q0vdWbWNQsry3mvHfTVgTY1tbEnbHJ8o3yDrvGBtKptLRtNPx/7Cf7e+uftV/GrV/DeseF/D9jZxaU+rRNpyP52jlbhYvsd2XJDSkPnIWPBRhsIyV+qtEuINW1PWLdrG0jXS7tbZGUhzKDBDLuI2jacylduTwoOfmwODLc4oY+j9Yw2sbtdtj3uJOF8fkWNeAzFKNRJOyaejV1qv67aWbjsZdUn0y3uJL7S4xNGjHNk4ALAYH+u9TirC2urOuVvtNIPIIsX5/8AI1ebftJfBrXPjj8GdJ0fQdRh024jmhuZjLMYknRYJAEJ8uUcStE/MbcIcbThh2HwI8Eah8Nvg54b0HVp4LnUtJ0+K3uZIHLxGQD5gjFUJUHgEqDgDIBr0pKCpqSl713pbZd7nzsHJys1pbe/6G19j1f/AJ/tN/8AAF//AI9UV1o2pXqhZLvTGA6f6DJkfj51fHPjL/gkHqtn4z8UeLvh/wDFjWvAfjLxVreraleajY2zxI8F7fG9SLZFLGS0TkqXcv5oxuAULGt/QP8Agmr8VtM+IPhzVNR/aM8ZeINE0WTTLmfRL9rp4buaznt7l2MhuS37+WKYktkxrMiDdFH5Tq0P5vwNNe34n1j/AMIref8APzpv/gJL/wDHqD4XvduPtWnY9Pskv/x6vnT9of8A4J6eIPjL8WPCfjGDx7bya/4V0nVNKtNV1LSgNQsjduxiuYHtXhiWaBXKqfK52IchtzN594c/4JlfGxNbtdW1D9oTXF1bQHvbXTZ1m1C6a4t55EYSu8t2XVtsVsxtzvtzJaxb45gJWuCPK1dy/AHHXb8T7M/4RW8/5+dN/wDASX/49R/wit5/z86b/wCAkv8A8er58/Zl/YU+InwK+M1jr2v/AB48cePvDdhYCCPRdUurple5MCRPPIz3DiQAqxVHDY8zJJkUySfUNRNpO0Xf5BGN1qrGCPC96pyLrTgR0ItJf/j1B8LXhP8Ax86d/wCAkv8A8ereoqOZlciMH/hFbz/n503/AMBJf/j1H/CK3n/Pzpv/AICS/wDx6t6ijmYciMH/AIRW8/5+dN/8BJf/AI9R/wAIref8/Om/+Akv/wAereoo5mHIjB/4RW8/5+dN/wDASX/49R/wit5/z86b/wCAkv8A8ereoo5mHIjB/wCEVvP+fnTf/ASX/wCPUf8ACK3n/Pzpv/gJL/8AHq3qKOZhyIwf+EVvP+fnTf8AwEl/+PUf8Iref8/Om/8AgJL/APHq3qKOZhyIwf8AhFbz/n503/wEl/8Aj1H/AAit5/z86b/4CS//AB6t6ijmYciMH/hFbz/n503/AMBJf/j1H/CK3n/Pzpv/AICS/wDx6t6ijmYciMH/AIRW8/5+dN/8BJf/AI9R/wAIref8/Om/+Akv/wAereoo5mHIjB/4RW8/5+dN/wDASX/49R/wit5/z86b/wCAkv8A8ereoo5mHIjB/wCEVvP+fnTf/ASX/wCPUf8ACK3n/Pzpv/gJL/8AHq3qKOZhyIwf+EVvP+fnTf8AwEl/+PUf8Iref8/Om/8AgJL/APHq3qKOZhyIwf8AhFbz/n503/wEl/8Aj1H/AAit5/z86b/4CS//AB6t6ijmYciMH/hFbz/n503/AMBJf/j1H/CK3n/Pzpv/AICS/wDx6vPPEf7LGqaj4mm1HTvib460uO5vTcyWgvPMgSNrs3DRIBtZQPMmVMlgu6MMHijEJk8Rfsu6pr2tX9wvxO8fWlnqDSlrSK++SFZFiG1DjK7GWR19GdVO6JWikOZi5Ud//wAIref8/Om/+Akv/wAeqrdaZNZz+U1zZtJtDFY9OuJMA5AJ2ynGcHr6GuLX9lq/e4mlk+JXj/zJjuZo9RMeWBUp04wAoBUAA46DdKJOg+I/w0ufGWvaXOtxe26afFKvnWe1bgNLBPAxjkMitE6rMWVvmGcZBIBpxk+v6ClFI0Pskv8Az2j/APBRd/8Axyj7JL/z2j/8FF3/APHK840f9k9tG0RrO38QeONP3Xi3ZbT7yK2wotbi2EKnzGkWNI7gLGFcFBaWuS7JI80+ofs5a/dXNmIfH3xKtbWys4bUKmoRtNcMtxPK8krtIQzMssaAhVYCBQWdSUL5n/Vhcq/q56B9kl/57R/+Ci7/APjlH2SX/ntH/wCCi7/+OVw3i/8AZ/13xT4ivtQh8bfEHRRJK72ltYXsYhgQ2iW4RxJK5cBgZTsMeXEZ6iQy24fgVeW3iPT71NU8QSJYW88SvN5T3geZrktKswlADAXLAAoykohYMUjKHM7f8MK39anXfZJf+e0f/gou/wD45TZo2t03SXEKr0ydIuv/AI5Xl8P7G6WVlp8ceveNr2TTEgS3fUrqKZU8nzWVtsckXzO0riQn7yO6gI2x09e1GC6m0SK0FlqVw0YVWlklhEkmBgsSrj5j1yMc9MVVN3dpafcEtFp+pT061bVJzHDeWPmKu7a+nzxkjjJG6UZxkdOmRV7/AIRW8/5+dN/8BJf/AI9VDwH4YvtFvY/tR1CYRQyI095JE0krM6EcR/KMBccAdupJNaPi3wMniu6t5/t+oWM1rG6RvayCNhuZCTnG7omMZ2kNyCQpDrWjO0HdfIKN5RvJWY3/AIRW8/5+dN/8BJf/AI9TJ/Dl1bRF3utNVRgf8ecp68D/AJbVjw/B692t53izxBJ+98xNsxQRDK4AGeeASS+7LHPAyp3NC8KTeG9Ikh+36hqjtMk266mMjjBXKqWPC/LkD1JyTmsuZmnKir/ZVx/z3tv/AAWXP/x2k/sufP8Ar7X/AMFlz/8AHazLP4UQ2mn2sYGorPavGVmjl2nagAAA8wjPG7Jz8xJ9ALJ+HrNawx+bqcawLIqpGYljG+RJCwXdwylBtOcKSeMZBrm/rQnlRaOlzj/lva/+Cy5/+O017GSM/NdWY+unXH/x2neE/CcnhVrllW8uGuhHvB2KilARlV3kKDnO0YUdgBxVjWdLutTZNkd9b7SCTFJGpYc5U8ng57YI6gg1ULN2en3EyVldIba6BdXcKyRXenMpzg/Y5R04P/LapD4XvSc/atOz6/ZJf/j1aeiW8lrpyrIux97sVyDjLsR046Gk1zRIfEFh9muFVofMjkKlQwbY6uAQeMHbg+xqJSs9C1FWKdto+pWalY7vTVz1/wBBkJP4+dRcHU7dwrX1gWIzhdOlY4/CU1zv/CmbpLOSKPxh4qVtu23c3hYwDYq4Ofv/AHc5bJ+Y4IPI2fEHhSTU7a3hZ7iRYgmZFILkqrrklmHzYk3K3OGUHHGCuZj5exL9r1E/8vlr/wCCqf8A+OUfa9S/5/bX/wAFU/8A8crBX4bXy7v+Jz4kYzRuku6aI+aWVV3H5uCFXjGACScdj0ml2k2l6bb23k3kwt41jEkjozuAMZYl+T6n1qub+tA5f61M60tW0m5uJYJNJtprx/MnePR5Uadum5yJMsfc1Pd6hqEVhJNHqGmOywyTIpsZBuCfe/5a9iQD9aNZ0u61Nk2R31vtIJMUkalhzlTyeDntgjqCDTbzTJ4NMkkePaqWd4GGRlS7qyjj2B6VooxSVrfgZylNt3v+J89+Mvi18SvCl9qceg/C2x8UaZYtZJYyHUI7FriFoFeaQN+8Mjby6bPLiMezd++3KtQeKPjl8VPDnxR1DT7X4Ir4g8MiUJYahba3Z28hU2aS75w7NjbcCaAiNWyGidcgNVnx5+1F4Q+Ec99Z61NfW8mjSiK4SHE0sVuNP+2/azEH8w2+1ZIt6qxMkMgxhGZaTftd6FceHPEGoWeg+M3XwzeJYXqXtl/ZoSdrl7fbvuHRcBonO77pBQbsyIG+gjh01flWvr5ee55PtGtLnovws8c6r420yaTxB4Hm8H3luIwYJ7uG8SZmBZvLeMDcqjYMsqncxG0bTnqd9r/z7wf9+x/hXzn4w/4KIfDzwCdRfWLfxdp9npsdxJJezWSrausN4tmxEvm7VzKy7fM2bgSB8yso7Pwf+0v4e8beM7DQ7Wx8VW9xqck8NtPdWDxWzyQicyRl9x2uFt2JVgCpYRuFmSWKMeF620+Ye2Wx6zvtf+feD/v2P8KN9r/z7wf9+x/hWV5H+1J/323+NHkf7Un/AH23+NT9XXYr2pq77X/n3g/79j/Cjfa/8+8H/fsf4VleR/tSf99t/jR5H+1J/wB9t/jR9XXYPamrvtf+feD/AL9j/Cjfa/8APvB/37H+FZXkf7Un/fbf40eR/tSf99t/jR9XXYPamrvtf+feD/v2P8Ky31KS7nvYZNNjs4be4t0t5sq32pWddxwB8oHTBOTnnHSgW+T95/8Avtv8aZ4Lu7bxVuk+z30aQXMabbkNGS6zxAkDPIBJX6g+lKVFQi5tEupeSinb9dDxz9tv41/EH9nv4dfC+4+HPw/XxhN4luYoNZvp7O91JbJPLi2p5VvIjiWYu5SR22bofLILzJj1346anrPgP9lrXvF3h3wNNq3jSw0M39t4fWSW8kFz5YLR7IiHuDGSx8uLDy+XsTDMtfy7eJv+C6P7bVr418Q2OifHjWrPSdI1W50+1haxsP3UcUhVVH+jE4C7RknPFVP+H6f7d3/RwGr/APgDYf8AyLXz9S6qt8zt2+bPXpxXIlyo/qK/ZA1zVPjR8GrXWvGGg2um6tIyAtaxXFrb3atBFI0kccsjuEWSSSIEuwbyS4wGAHL/ALNHxJ8T/FH4s+ItH8UeE7bSdP0+XUFjRLG8tptMMF4sNvFPLJKyTtPCzSpJGqIyR703o6tX8zv/AA/T/bu/6OA1f/wBsP8A5Fob/gup+3cq5P7QOrADkk2Nhx/5K15v1Wvy0Y/WJXg/edo+/wC61aWmmrT0tqjp5qV5v2Ufe2393VO6/LXuf04fGjx1r3gb486B4f0bw5a3Wi3wsjKZLK7uLi/M1y8cwglSVY4/IjUSOXVwoYM+xMPXRftRalefCjwFZX/hzS7GS4udQW2ubu9guLu10uDypXM8kccsbFd6Rx53qAZgSeMH+Wlv+C737dSHn9oXUx9bPT//AJFoX/gvB+3Q+3b+0NqR3DIxaafyP/Aasp4LEuFeKxM06nwu0f3fupe7prqr+9fc0jWop026Mfd3397W+v5aH9T3w31DUvEv7M+m+LNT8GXFv4sudB/tF9CJmtJJbnyi6w+XITJAZCF/dyDzI9+1xuVhXFfsQ/ELxX8dF8dJ448HwaTb+HdZFlo+q29jeabBrMBjBfbBcSvJuib5XcNt3u0eA8Mmf5mv+H6f7d3/AEcBq/8A4A2H/wAi0f8AD9P9u7/o4DV//AGw/wDkWu7lqe1VT2jsk01pZtta97qzXbV6HP7nI48ive9+2+n9dj+j3wv8cPiPqf8AwUXvPhpefC9IvhqljLMmtrb3ay2pRXMdxJdGT7PJHKyIiRIgfdM43f6NJuzP+Ck/7Q3xO/Zd8U+ALX4W/CpfHVrr0039pM1jfXrSsjRBLOJreRVt5pd7Ylm3IFDuEcRSCv50Zv8Agu5+3Vb/AOs/aE1SPjPzWenjj/wFof8A4Lv/ALdMZG79obUl3DIzZ6fyP/AatoOSVnJv+vUmUYt6RR/WN4i8N2+lw61JY6Yb+6s9NFxa2glYefN++wmc/wARVRXEweM9StoWjuvhjr0lxCyo7QykLJnblwNzKMbjuUO+CjBGlXa7/wAsPiH/AIL7ftyeGbH7ZN8ftZdGdYi0VhpzN0JGf9GHHX8/esT/AIiOf22P+i+eJP8AwW6d/wDI9VzvuyFTS6I/rLsdZvGjk+2fD+9t5Eso7lfKvZZkLtDC7qT5YOI5HkRgoaRgimOKQl1jxrLx7qy/ZZL34V69DDcQjzI4Z3lmtpVMnmBgPlK/LHtKsdxY4yBmv5Tf+Ijn9tj/AKL54k/8Funf/I9H/ERz+2x/0XzxJ/4LdO/+R6OZ92PkXZH9bvwvjfxnDdLrPhG48PXFrtxvuZJI58tIPlYheiopOMgeYACcZPWf8IDpP/Pr/wCRH/8Aiq/j2/4iOf22P+i+eJP/AAW6d/8AI9H/ABEc/tsf9F88Sf8Agt07/wCR6OZ92HIuyP7Cf+EB0n/n1/8AIj//ABVH/CA6T/z6/wDkR/8A4qv49v8AiI5/bY/6L54k/wDBbp3/AMj0f8RHP7bH/RfPEn/gt07/AOR6OZ93/XzDkXZH9hP/AAgOk/8APr/5Ef8A+Ko/4QHSf+fX/wAiP/8AFV/Ht/xEc/tsf9F88Sf+C3Tv/kej/iI5/bY/6L54k/8ABbp3/wAj0cz7v+vmHIuyP7Cf+EB0n/n1/wDIj/8AxVH/AAgOk/8APr/5Ef8A+Kr+SjwH/wAFsP8Agop8T9OW98PfEz4k6xp5fy/tlt4cs3tVb0M32XYDyOrd69h8F/tvf8FNPFUUMt58cm8OwXChkk1KXSW4zjJWC3lcfiv68VPtLfaf9fMPZrsj+nb/AIQHSf8An1/8iP8A/FUf8IDpP/Pr/wCRH/8Aiq/nD0v9pL/goVJExvv2ttKhfJWNLaytZzL6YDWaNzg9QCMHOKvt+0L+37JJth/a6WUg4IGi2bEfUJbtj6nj3o9qv5mV7PyR/Rb/AMIDpP8Az6/+RH/+Ko/4QHSf+fX/AMiP/wDFV/N9qX7TH/BQ+GBBa/tXafJdMeY7iytYVI5HDLZuSeOm0Vx3iz9tH/gp14bmMdr8bptclUM3l2T6UjYXk8T28R4546nHANHtV/M/6+YvZrsj+nL/AIQHSf8An1/8iP8A/FUf8IDpP/Pr/wCRH/8Aiq/kr8a/8Fq/+Ci3w6hkm1r4l/EjT7aLO65k8PWZt+Ov70WxQ49jXFf8RHP7bH/RfPEn/gt07/5Hqufzf9fMXIuyP7Cf+EB0n/n1/wDIj/8AxVH/AAgOk/8APr/5Ef8A+Kr+Pb/iI5/bY/6L54k/8Funf/I9H/ERz+2x/wBF88Sf+C3Tv/kejmfd/wBfMORdkf2E/wDCA6T/AM+v/kR//iqP+EB0n/n1/wDIj/8AxVfx7f8AERz+2x/0XzxJ/wCC3Tv/AJHo/wCIjn9tj/ovniT/AMFunf8AyPRzPu/6+Yci7I/sJ/4QHSf+fX/yI/8A8VR/wgOk/wDPr/5Ef/4qv49v+Ijn9tj/AKL54k/8Funf/I9H/ERz+2x/0XzxJ/4LdO/+R6OZ93/XzDkXZH9hP/CA6T/z6/8AkR//AIqj/hAdJ/59f/Ij/wDxVfx7f8RHP7bH/RfPEn/gt07/AOR6P+Ijn9tj/ovniT/wW6d/8j0cz7v+vmHIuyP7Cf8AhAdJ/wCfX/yI/wD8VR/wgOk/8+v/AJEf/wCKr+Pb/iI5/bY/6L54k/8ABbp3/wAj0f8AERz+2x/0XzxJ/wCC3Tv/AJHo5n3f9fMORdkf2E/8IDpP/Pr/AORH/wDiqP8AhAdJ/wCfX/yI/wD8VX8e3/ERz+2x/wBF88Sf+C3Tv/kej/iI5/bY/wCi+eJP/Bbp3/yPRzPu/wCvmHIuyP7Cf+EB0n/n1/8AIj//ABVH/CA6T/z6/wDkR/8A4qv49v8AiI5/bY/6L54k/wDBbp3/AMj0f8RHP7bH/RfPEn/gt07/AOR6OZ93/XzDkXZH9hP/AAgOk/8APr/5Ef8A+Ko/4QHSf+fX/wAiP/8AFV/Ht/xEc/tsf9F88Sf+C3Tv/kej/iI5/bY/6L54k/8ABbp3/wAj0cz7v+vmHIuyP7Cf+EB0n/n1/wDIj/8AxVH/AAgOk/8APr/5Ef8A+Kr+Pb/iI5/bY/6L54k/8Funf/I9H/ERz+2x/wBF88Sf+C3Tv/kejmfd/wBfMORdkf14fEHwjp+leDNQuLeFopoYtyOsrgqcj3rh7+6uG1S6tW0/bYi0aQXZkBDvyPL29enOT+XSv5qP+Cen/Bd39rb4+/t5/BjwT4u+NXiDWfC/ivxtpGlatYSWFiiXtrNeRJLExWAMAykqSpBweCDX9M+o/wDHjcf9c2/ka9jLWnTd9fX5Hm42L51bT0Pi74u/8FMLL4T+M/EHh/XfGuk6T/ZepzaY9nc2ccz7BaG83siI7CH7OGzLIFQtGy5LbQ0nwv8A+CkV18Z9T1a18M+KDqVz4fma21BX0Ca1+ySrLLA0ZaaBBuEkEqlQSfkJ6YJ9y+M37PXgPwzpEcmrN461u48XXRs4NF077NctqUsyPJJEsTw7fLCByxkbaqAljgE1a8M/sw+CPHPhq41SO8+IEK2ck0E0F9Jbw3EMkXDqVMBH4gkH14r6WlmmXRinOKt/g1/Py3tqeHPL8Y21Fu/+LT8vwueY3P7T/jS7haOXUrWWNsbkexhZWx0yCuKJP2nvGksyyNqVq0iqUDmxhLBTgkZ29DtXj/ZHoK7jx9+z34H8B+LNP0NLP4peINU1K0mv44NHNjMUhikjjdmMiRgfNNGAOc7vY1teCv2SPAfj/wAK2OsafqPjIWd+paMTXFqki4YowYeQRkMpHBI44JFbvOMoUeZw/wDJUZLLcxb5VL8Ty3/hqDxp/wBBK2/8AYf/AImj/hqDxp/0Erb/AMAYf/ia9Wvf2Rfh7p8tikmveJd+pz/ZrVUvLaQzSc5AC256YOT0GCTgA1cX9iLwa13JD/aPizdGiuT9rtsYYsB/y7/7Jqf7ayhbw/8AJR/2XmP83/kx47/w1B40/wCglbf+AMP/AMTR/wANQeNP+glbf+AMP/xNeraN+yL8PfEV9qVrY694kurjSJ/s17HHeW263kxna3+j/UZGRlWHVSBNrP7GngXw/YtdXmreLIYFYKXE8D4J4HC2xPXvVf2xlXNy8mvbkF/ZeYW5ubT/ABHkf/DUHjT/AKCVt/4Aw/8AxNH/AA1B40/6CVt/4Aw//E169o/7GPgXX9LhvbLWPFNxa3C7opFurcBx0zzbZ7VY/wCGGvB//QS8Wf8AgXbf/I9T/bmULeP/AJKP+ycy/m/8mPGf+GoPGn/QStv/AACh/wDia7/9k348eIPil8SJrPUbtZrOO337DaJC25bq2AbIAOCGyPUEV0//AAw14P8A+gl4s/8AAu2/+R66T4Yfs0aB8JPETavpl5rs9yVitil5PDJHte4hJOEiQ5+Ud8deK5cbnGV1MPKnSj7z292xth8tzCnWjOpL3Vvrc/jvvP8AkevGX/Yy6h/6NNOpt5/yPXjL/sZdQ/8ARpp1fD1v4j9T62n8C9Aq1oOtXHhrXrHUrNlS8025iu4GZdwWSNw6kjv8yjioJLaWHTvtjxSrZ+b5H2goRF5m3ds39N20E7c5xz0qKOZZiwjYOU+9tOduemazLPsf9l7x38ZPiFY6b/wjHhv4bzaOtlc3dq19bNbw28yzCFN0xLSNIrxbhArESJLclwTd3LTdD8Y7b9o5vD/jWXxFpvwxksbiRptWvbRlV9UPlXgN5EUcOz7TKqkKsxMhCIQ1yK+dfB93+z3BPp6ePtA+LlleWdvbG6i0a4sNmoN9hiZmZLrDxiW7eRgyOALZIwq+ZKXhj1xf2aYdMuhpMPx0a7ktZBZXV7LoiQx3YEjIskSITJEc26sVlRlDSOFPyRkA8mT7i/SloXOOeveigD2r9k74l+PdI0vXPDvgvWvDvhkI0Wu3Gs6hPLazaSY7i1jF1FOhPl+SdkrEITsR2w7JGB2nwFuPjFa/szfEDUPDeueDbXwcNQv59e8QX10ZNTilL6ekt7AcPcgjfFLG8UXmkrcSIGkhUx/MsGlz6jHJJDa3FwluN8jRxF1iGQMkgcckDJ7ketNGizXskfl2css0jtDCRAWLSKASg4yWAZSVHIDD1FAG1/wUI13xT4g1HSZvF1r4dtNR/snTJIE0S1it7VreaB7lHZYwFadmndpm5LTGQsS2SfmOveP2tdW8E6zplhN4B03WtL0dbazjuotTu47qaW+WJhcSqycBGbBA45ydsYYRp4PQAUUUUAFFFangzwRq/wARPEdvpOh6ddapqV02I4LdCzH1J7Ko6ljgKMkkDmgDLrrvhT8CPF3xu1FrfwvoV9qnlnEsyKEt4O/zysQinHYnJ7Zr7C/Zr/4JY2NjBa6h45nh1LWN6u2lIzfYrRSDgTOpV5HJxwpCjDcSjg/YHhrSrLwL4ct7XTfsOnrp4KLp+maN5VpGmT0VjujBI++XTJLfKAQRnKouhSifJPwG/wCCMK3otbrx5r91NIyGaTTtEiyEUMAd07g7sH5WARcHOHPBr6u+Dn7Dvw7+GktvD4f8E6THfbhtme2fULzeR0WSQF+eu1W/BB06KLXbjVxCv9tWduFKq3nWau5fjuMFgMDG4b8rgEDcH6i/07UtQ0yQf25cSK0QWGOO0jjPnHgLlhgDkkhckIjEsoxjOUmyrG9e+A59D1myuNSg0m8vr1hFFDJqUDX0gRc7wfKuAEVVyTvG0ALtHCjWXw/DbadN9rsbeDYcxmymur1Z5CSCCNsSj+EAphmzyOBnl7D7foEMiW95c6d5yEzypa2Uk1yRyRkRs5UcFfMbK7QcMSQMDxd4ijt1khHirxJZSSOkMc2bZ3jUnB+7AnzBdzEt/dPPpmFmdzaeQLeSYTXi2/8Aq47eSbc86jhnaPLBizD0I2hSOM1l3+uRSkqsdnJZ29whghN3IqSNIfKJeNUCKBvJyu7JHY4K+YyeJ0GmXVmviS8mtnJSFBpsECRoAcbjtJbCgYKhDkHAHeLULebXtNja119mjgaGZ0gs0i3jzFxtUg7cMQSTkYBHUBjWgHtVrr1nGoS+05I12Kx+zyzTIrMASyknCEEHBIPAGMZIqCz8b6brwuLZo2WSLPnBXaHceSGxGwI3AEHcOMNwdteJ63p2ttYyXA1zU928sIY/LGDjqAI8dBjg7h75Nc/rqX3h25t7hrrUIZrcCQZMfnBP4mxtzxhWwOSVwMbqnmTK5We96kdPu9ytHDb2txPhpoz8oiwpBchRvw+4Y81VxtwCASfHPjT+x98O/jDNNHrnhPTtQuWJxe21r9kvf9nLw4c45IGWXsVPJoji8YX+jRtbarfr+8G2eO2gjVgfvBSfv9WAwQABjjdxDpet+JPDStDe3d55CkKiSWiRiHjnnBAG4np90MOi520muhPKz5D+M3/BIVrdbm68C+ImbaSYtP1cDc4HUCdFB3cgANEFB6uBgn5H+Jfwa8VfB3Uxa+JtB1LR5HJEbzxfubjHUxyjKSD3RiK/X3Ub6e+LNDeTLIxwLeZA8bgZA+VSg3DOAcZzjHcViX2tT6hoctjq0eg6ha3DMLzTr7SvtVvIowULqzsrZbcM7SuSDyQQdI1O4nE/Heivtb9oT/gnLpXjDULrUfh3eWek6s5Lt4euyYLaVv7ttLIzbGJx8kh2fN99AAtfHfi/wdq3gDxDc6Trmm3mk6nZkLNa3ULRSx5AIyp5wQQQehBBGQa0jJPYjYzaKKKoAooooAKKKKACiiigAooooAKKKKACiiigD6G/4JJ/8pR/2d/+yjaF/wCl8Nf2O6j/AMeNx/1zb+Rr+OL/AIJJ/wDKUf8AZ3/7KNoX/pfDX9juo/8AHjcf9c2/ka9rLP4b9Ty8d8a9C78QPBVvr/guzur2bVNOOnmK5s7/AEtPMvrOVk8oNEojlLFlkZCpjYEOcjuIfhN8LNP8PfDf7Loeo3etWuuB9Uk1a7vFurjU3uRu+0u6hVbcu3G1VUKqgAAV4j8VvjV4RfxD4v0m/wDBt1c32sWtnoWqX66pk3dvZSSvAgjkR40RXnnbaFwTKxOSc15746/aP+EWseJ9NsfE3w/1S41Pwv4fFpb3EniOaAx2VsAz7kgK4IDZZjGocZUFtpQVHJswcU1H3XZrVf5/1qL+1MEnrLXZ6P8AyPpDxtD4T8ZeIrDxFb/Ei38O32n2M1sl5pWs6biS2lKTuG8+OVdv+jq+V28ISSQOO4+H/wALP+FceDNP0Oza6urbTkKLNdSRtNKWZnZnKKq5LMT8qqPQCvjtP2mfgrjzm8NN5lvIytcS+PboT+dCzxtI0jSb2lEkLsZSS7SRmQsXG+vQP+HtfgzQnWx/sWO1+zhYliF6VVFx8uP3ONpXBBHBUqwJUglPI8xceVw09Y/5gs2wV7qX4P8AyPoq0+GFvY+JptYi0+NdRuI/JabfnapOW2jOFLHG4gAttXOcCr0fhq6jvpJtnMiImNw42ljnr/tfpXzpc/8ABV/wzYtarcaNHbfbbX7dE02piJDBxiRmaIKg5A+Yg5468U9/+CrXhmPUY7NtMsFupgzJGdciywXYCR8nQF0GfVgOvFJ5DmHWH4x/zH/a2DX2vwf+R7F4F/Z10P4a+I9S1bRdLurO+1jP2tn1a6uI5MuXOI5ZWjT5iSNirgEgYBxXSal4Rk1fT5rW4txJb3CGORPM27gfcEEH3BBB5BBr5zP/AAVs8I7ICtjpsrXShoI4tdikln3IHUIioWYspBAUEtuXAJIBkP8AwVd8MpOsUml2cEjKDsm1qOFgTu+UhkGHGxsocMNpyBiqlkeZSlzyhd9+ZX/MUc1wUVyxlp6P/I+irLwrJptlDbW9rHDb28axRRoQqxooAVQOwAAGKl/sK6/55j/voV82Q/8ABWvwjcaX9tjstMa18sTeYNeiwVIUggbMn76DA5yyjqQKuan/AMFS/D+i6l9jvdHtLO627zFPrcUbAEhQSCgxkkAZ69s4NZ/6v4/f2f4x/wAyv7Ywf8/4P/I+h/7Cuv8AnmP++hTLvTprK13SJtVp7cA7gf8AlvHXz/on/BT/AEfxKsjaf4d+2pDjLw6mrIwOQGVvLw65Vl3KSu5HXO5GA7j4S/tVRfHjV7rS49Dk0trNYLrzGuhNvxcxLtxtH97OfalUyTG0o+1qQtFbu6/zBZphaj9nCWr8n/kfx23n/I9eMv8AsZdQ/wDRpp1X9I1y10P4heOHutD0nXFk8R36rHfyXcaxHzj8y/Z54WyenzEj2zzW9Y+NtHv76C3/AOEE8CW/2iVYvNuL7Wo4YtxA3O39oHaozknBwATXmVvjfqehT+Beh6T+xJ42+JF/4sh8G+BfFXg/wzG8suotJ4k8iGx3zy2FvJJJM8TnCeVbyFTwEhm4be0cnc/ET43fHL9k34d+CdPudQ8GWul3GjGOyNqi302pQl4n864M+7MuUSN0i2j5JRNH/pMxuMaD9lD+1dO+1JB+zta2slxJbW8eq+LdWsrmdk2BiYjfN5S5fhpGVSFY5xXF/Fj4eW/wd0bT7268N/BnWLe+nntI10bxBrFzJA0SwyNvja+R0B+0gDjlll/uk1mWeieEf+ChXxe+N/xV0/S7ObwLpLalbXlntn0qeSxtI5IJnmuJDme6by1LzBV8zLIQIpPNljm7Lx94q/aFn+Herf2p4s+FtrotvY3QntbGS1WeZJUk85YFgjMvnSLvAaPDkeUwba8LN5n4O/Zvs/H/AIQ/tS2tfgXYhbe0uJLTVte1izncXFsk6mJTft5iK8i2xb5cXKTx4zGC6eKP2V28IpftJp37O97JptvLPNFp/ijW7qQmNEcxKqXR3SssilEHL4l258i48oA+co+EX6U6uoX4haOyg/8ACvvBnP8A09az/wDLCj/hYGj/APRPvBn/AIFa1/8ALCgDe+Ev7XHxI+BPhmPR/CPiibRdLh1Qa0luthaTql6BDi4Blidt6m3t2U5+V4InGGjRh1nwf+OXxW8X6p9u0Px14X0G+8A6vD490q1vo9M01bzWfNtrNGtYWgEM9yRJ5rRygQlUuZXPmSN5p8FvhHbfG/Sra7tdL+Cfh9brUJNOC69q/iO0ETobPLySrcPDGjLdlk3SBpDazRorTNbRXF67+Atrp/i/wjol7b/s+w3Xi/Vl0iNl8U6zJBpbFYma4u5vtnkw26+dF+9MhVw2+PfGrOADxz/gof4y8XePNc07UvG3izw14y1q40rSpUv9CNr9mggltfPjtH+yxRRefB5pilAU7ZI2UO6qrH5ir6Q/bq8ASfC9rPRbix8C2twqw3byeFtWudStpBKr4SR5p5SsqFWBQbCufmBypHzfQAUUV7d+xd+xvqn7Uni2S6njntPBuiyKdVvUcRPMeotoGYEGZl5yQVRfmOSUVwDlv2df2ZPEn7SXikWWjxLa6dbsPt2qXPy2tkvu38TnsgOT1OFBYfpb+yz+yTofwR0RrHwvpU+oak8bS3l/PxNdBOrO+BsjHG1RgZZFG53y294J8LQ/C3w/b6X4f8O6fp+nWoAs7SOVSqH7wVBu3s+TksSXdvvHcRnU1Dxfd6NazWNtpd15ispuLgtbyLJKpO1lXKrsX5vLjA2g5bHrzync0UTf36fpttNa2E01xdW+VkFjATGg2/P5ZUMNpYtljxhVJyEAXi9f8UjVdE+x2M1jDGpKqkB3Myk5d2cswYknCnJDLljk7TXIeIvjPrHiGW80fTbO8NjcI321Y2iYzgKxHJbrs4z/AHRkAfJtwdJ8XXZ8ySOwulA2xxjfF8p/779uMVmUjvvC8baTuuGmaaSH/VRburdAcdeCc88nHccV0yfF7UDY3GoLalo4VKRIqqS6EhnkHAHzNgZXPyqMH5mz5PL4nunS302GyvDJecyt5kQIUfeOQ/pgZ4wWBreHi1NE1MLc6feDdgBEkgyE2jqN/TtjtS1bKskXpvi9eajDNa3Vrgu26PDMWjOQPX04wePbIzXVfDu7tdX8SWsd9bwz+TblzG+QqSSMUSQ7WH3VWXljj5xnNYXw88WaRqGuagn/AAjNzILw4t45rq2QryAApdyQxP8AtYOce47vwHqdxbNql7p+i29jcXErwQxy3kLwxiJVjKk+WzBt8bMSrADewyTmqZnudUvw/sdGRbrUI41g2hsQsfl+YZDMPl56ZGRkgc5OM/x94i0zwt4X1SOGzutPZbSSZEWyZJEQxkqx+XPzcEMcZB467jHda9fWmhX19daPJd3lgWktz51pLCo+baxx5bP/AAnBRV6jb94t494u+PnijUdG1W1uJNSt45LacGOCS3gRdyNk7UcDnPPfnvxRzFct9z2HSNUj12+vJLZrWW4gV3aWSaOTYAccBDlT0xuUL05PNYl38RNL8BWaxR2sGtMJTI8UkKSDcc/xDGFHsx7CvPvEPxi8SWmkTR3lrdTBAUSd3gaQB8Ehm3FiMjOcgg9CAxB4fTPiZeQuVa2voVYEsY50AJ/BvYc9aNdwsup7rH8S9J8Z+HZV0+zttFubImKztJZGW3MZwyRlt+8KqsyAlxuMbZzlsQ+CpNZnH+m2drDIZPLktopvtCyA4MbKpdigb5hg5BOOQCFryXSPE9x4a1e3vBp9zNb3Qa3aJngdWYqWU7S/HAkG4YPz1pza3Jefvv7L1cSMwa2MXk7dvRlAEucjjgZzS13ZSiraHrmreA7e61bztPmaOGFWeS2Yqg27jujywUh1BB2jOUDHGI3Nc74i8ErFFcLcTPb3Cn9y38Jz94Mc4Hbg8McY9Rg6T8VdV+zQxNY3cqQMGSSQwvIq9tr+cG2g4JUEBhuU8Eg93oPi1/GOgGO60W6XcjLBJDLBJE5VipjyZBgqVbgZPtginuTqjgLr4Z/2nos073Fv59qCZIlO1xzhXTP3l56jkdOxI8++K/wJ0T47+FP7G8ZW8rra5TTdYi4utLcnorH70ZJ+aNjtOcjDYK+3+JtDdbFU/sm+tZUYm3uG+yuNp7MfPGFJHUHJB9QpGVrtsy+GlljsJZ/Od1kV7i3k2FQCyvtkPltyNpyyMPmBAyQ9tUI/KP8AaL/Zt8Rfs1eNn0rWofOtJizWGoxKfs9/GD1U9mGRuQ8rkdQVY+fV+sXjLw9pHxT8FS+F/Evh+51zTZlLxxu9ulxGy5CsH83cJE5GUwSpIIIBr87v2oP2ZdS/Z58WY8u6ufDmoOTpt9KELMOvlybCVEi/UbhhgBkqu0J3IlGx5dRRRWhIUUUUAFFFFABRRRQAUUUUAFFFFAH0N/wST/5Sj/s7/wDZRtC/9L4a/sd1H/jxuP8Arm38jX8cX/BJP/lKP+zv/wBlG0L/ANL4a/sd1H/jxuP+ubfyNe1ln8N+p5eO+Nehy2s/sMaX471m41uXxBqVvNqj/a3iSCMrGX+bAzyQPesC8/4JZ+E9R8STavca1qk2o3NsbOaV0DCWE5BRkzsOcnkjPJ5r6T8Of8gOz/694/8A0EVeqP7cx0UoqpottF/kV/ZOEerhv5v/ADPlW3/4JL+A7NoTDctD9nx5YjsIVVMMrcKBj7yRMeOWhhJyYoysaf8ABJDwDHFHH9qmaOHd5avaRusQLtIVUNnapd3baMDLHjmvq6il/bmO/n/Bf5D/ALJwn8n4v/M+Vbz/AIJOeDNQ06azm1zXntbi3Fq8XnOEMQ+6gAf5QnVMY2N8y7W5qF/+CQ3w8cMDLw6urAWMQDBz8w+h6ewJA4JFfWFFH9uY7+f8F/kP+ycL/L+L/wAz5Rsv+CR3w/06SaS3uHhkuJPNkkSyiWRn2bN27rnZ8uQc44pY/wDgkj4BiMhFzIzSnLs9lEzHgL1OT0AGBwMV9W0Uf27jv5/wX+RLynCPeH4v/M+T7j/gkN8PLvT1tJJfMtVaN/Jaxi8tmjO6NmXozIclScld74xvbNi9/wCCT/gnU2ZrzVNRvmZt5e8jFyxY4BOZCTkhUUnuqIpyqqB9UUUf27jv5/wX+Q/7Jwj3j+L/AMz5n0n/AIJk+GdBa4Nlrd9a/apDLL5drEu9iSSfxZmYgcFndvvMxPZ/C79lex+BGqXGqWur3uoPdiC1Mc0SIFH2mJsgjv8AL+tey1n+J/8AkFr/ANfNv/6OSlUzrG1Y+yqTvF9LLv6CWV4Wn+8hCzXr/mfxI3n/ACPXjL/sZdQ/9GmnVHfXKW3j3xg0jKoXxPfnnbzibP8AECv5qR6gjit74ueO9H+IXxS8Ua9o2kWPhXSte1W61Gz0W3njkg0eOaVpFtYjHHEvlRBtiBY0ARVAAxXnVvjfqd9P4F6GH5Kf3V/KlVY41csv8PBB27TnqeORjPHHXrxg9D8WviNovxC8WxajpOi2Hhm1j0ywsWs4JICsstvaxQS3J8mGCMPO8bTOFjHzytkseS34k/EjRvGnh7wla6foGk6BceG9BGk39zbSRmTX7gXNzP8AbZgsaASbJ44ed7bLaPLsazLNnwZ8O28GeJLLWfGPhS81LwzYlp721BK/afkby0fy5opRG0hjEmySNwhfaytgjqtZ8afAdvDd/Dpvw78YR6tNA8dnc3mteZDaSFW2yNGjqZMHyzt3AEo54EipD3nx0+PvgvxV+zda+H9PTwrb6xppvZZ9TtL9ZL3WxcvAY0mQkkeQsRVQuFAdjtVi7P4GfiVorfBFfCv/AAj+j/20viE6yPEYkQXn2Y2ogOnkbNxh8xRMMyYDbsJli1VKNhJnPDgc0ZrpvCvxQ0DQPhD4z8N3nhfRdW1jxNPps2m+IZrjbeeHRaySvNHCu0hluVkVH5QjykOWxiqPgj4iWXg6z8RRyabomrya5o8ml2730MM40ySSWJjdRB0YrMsaSojI0bI0ofcQpR5GYrRqzZZVJ6ZIrpfhzqHhDTodcg8VaLq+o/2jYpbaZd6derC2jXH2mF3ujCy4uj5CzxrE0ka7pgxOVBE/wI+LHh/4TfERda17wrofjvT10++s/wCydSmVLcyz2ssEVxko/wA8DyLMg2/fiXkdap/BX4jaT8Lfin4a8Qavoej+MtN0O+iurvRNRZPsurxofmhk3I67WH95HHqp6UAc3+11rHhHW9N0+XwX4f1Lw3pkdrZQ3Vte6h9tkmvVif7RMr4GEdui4A4LBUDCNPBa9Z+Ompw6xoVxc28Nrax3GoeattbEmG2DeYRGm4ltqg4G4k4AySea838JeFNQ8deJ7DRtJtZLzUtTnW2toU+9I7HAHoB6k8AZJ4oA7z9lj9mbVf2nPiENNtWey0exCS6rqPl71s4mOFAHG6Vz8qJnLHJ6KxH6s/Dv4e6N8MfBWl+GdDszpuj6HE/lwEfcXALTzNgF5GLAsemSy8blWuF/ZU/Z9sf2evh9puh2bf6YxE95eIv727uGyplRcbj0KxqBkKh6tIGr1i38NW+s+Irhb63jltdPVRNCZcyR7sP5ZfcMS4cNIwwQJoF42lBzzld2LSM3UdPmN6bi6VrdWj8mIKBI0KEjjJ+XfjJYjKg7ck7cnldZ+IOkrrV1/bj3EsbiPy4yreW5YZEYHvlQxI+VVPUnI0vif4l0nQB9jgmWx86N2DqhCB/mkJIJwqFhjuOQoAUgV4faeIl1HxZ9shU3i2pZVa5USCeVhhpCpyCQCADgYweKzL9C3f3yrdTfZ/3atI2zYojBBOfujgAn+HkgYHQU+I4RVZmkZACuBjLHOMfz/M1GPDlzYhvMjkIznI6N+P51uQzWeheGJ9Rk09LjUi6pZzy/PDFIWAT92RjO5uckghhlcoDQitiHwvbahqF5f6hJ/qbYCFFJ27VQlSfqWz35ULxVixkS5dmKtJI7ZKgjce34frRpWs6botrb29vpfmRwqA/2mcyvclU2x5+UbVVtzbVwWGFYsA25/hRlR9sR3ySMCpY9uT/SrSsjPc3/AIXSR6X4ruLq8tV+yw27zOzH7kYwTkjsMA+vB6ZJHovhOxsdA02xgmvP9NW1Vp/NK7llOWkZnwSzbySewGAAMHPktzfSaaJhv2tdobF+PuCYiI5z6b8/UV0sPjKPUZVjW0j3TB/NkZgojDZywJ6EZzknsBUS3Kid5438WHwd4PNnqMEyC9t5GbbIMyEnCSBgvbPKkc8g+3hvjCMazpky6fHeeW8JB87Ac5Q5GV4Pc9PT6ne8a+K2nW30+JruSGEh08x9xclfvBclRwcDqcE0aBYxDTmWazWW4Sb5JpGV0j+aMr+6wA2NjDDllPmHIwAKIrqF+hw8V5efYbY3fmvHJEsgQrkYIBAPpUkDQ3E0cke6NgMnAyOhPPtWxpcGl3HgjSY2sZvOkhtpLm4aUmS5Rdzsi8fu96siblO5RHkHLtVPWIBPrs11bxx2kd5I8qQRArGqEt8q/wCyOV+gxWhI27vGj0qbyd8iwgSxgLgCVGEir7btgGPrXUPK02mrJDIoi3ZKoT86kZUjHfk8j3/HCshHc2ywiNYzG+9sHlskAfXGOvuPxt+FdTWw0iG3eRT9ld7RS6kttjYome/Kqp9PmrOUSoyaNzwzE8jH5U8scHzOrdh9D19vpXceHrW50CZZY2QWWpN5csRTI86NcqRnJBaNMEjH+pXuwrzVPEB0a/XfGrQyAqGzgDnPb+vHPau0iiXxDZapp/2j/SJIUhs7gzDyYcN5iSDHBJbZls8KCO5pxiEmenWniWHyIbVFm8vfiZkcefbtuwwiboVZXb5GGMg5yDisvWZrnRNX8+6ke6scG2uZoriOVbdkZ4t0gwu3BDkkjDRsSS2BXO2d/wD2DplrNDCFsb1PLna4lSWQTqStwshxlZA2Fx0Ug7ccgN+MniBtW+Hn9oW9xFcyOxiukkXypoyQqr90DeCqAA+i4IOMluNiTP8AHugXnhubzmXzLXPlOWwvl4xgHucEZGeVOO+COD8baDo/xP8ABl9pfiW0a6068RornK7mXJ+WZTyVIJyGAO0jvxmv4a8dato9tNpN9d/2hYiNQvnESAofuc9eMEdc/J2zTdW1PTZNZi8mzjktVlRTJgq6lSx2buuxg3Of7oxwoBSKPzj/AGhvgPqv7PHxIutB1LdNDky2N4E2pewE/K464PZhk4IOCRhjwtfp98aPgFaftJfD+fwvqUMcWr28fmaFqDIwNnKPuKSOfLkGUZcH+HjKoV/M/wATeGr7wb4hvNJ1O2ks9Q0+ZoLiF8ExupwRkcH2IJBHIJFdEJXRnJWKNFFFWSFFFFABRRRQAUUUUAFFFFAH0N/wST/5Sj/s7/8AZRtC/wDS+Gv7HdR/48bj/rm38jX8cX/BJP8A5Sj/ALO//ZRtC/8AS+Gv7HdR/wCPG4/65t/I17WWfw36nl47416Hpfhz/kB2f/XvH/6CKvVR8Of8gOz/AOveP/0EVerxpbnpR2QUUUUigooooAKKKKACiiigArP8T/8AILX/AK+bf/0claFZ/if/AJBa/wDXzb/+jkqo/EiKnwP0P4pND8ca54G+IfjibQ9a1jRJrjxHfpLJp19LatKomJCsY2BIzzg1u/8ADQHxA/6H7xx/4UF3/wDHK4+8/wCR68Zf9jLqH/o007NVW+N+oU/gXodd/wANAfED/ofvHH/hQXf/AMco/wCGgfiB/wBD944/8KC7/wDjlcjXYfCrSvA+qW2o/wDCYaprOl3CzW4sTZ/6toyJvOL4gmJO8WwyNuxHmkCzuiQSZlnr3g+0uPEmnaXcXn7UWqaO15YxXl1BcaldmWzcxRPLDj7YAzq7tEoJQu0TsyxptY29d8O3WlaHr13b/tWPqM2lsVsLWHWbxZNcC+aS0W66/dqQsLIJ/LYichljkjaKub0/wT+zfEt59q8d/FG52WUkls0ejQWrSXId/KjZNkow8aoZDvAgkl2I14kZnan4o8D/AADtPDKvo3jvxxeaxHaytJHdaZ5NvLcCItEqFYCQjSYVi3KAZHmbvkAODX9oH4gFf+R98cf+FBef/HKX/hoD4gf9D944/wDCgu//AI5XIr93migDrv8AhoD4gf8AQ/eOP/Cgu/8A45XpX7JWs+Ivj98aLbwz4k+MnivwfpdxaTTNqt54ovLe3t2TaRvYCVsHJACxkkkdBkjwevSP2T9B+HHiT4zW1n8VtSm0fwbJazNcXkMDzyxSjaY9kazQ7iTleZAAGLfNtCn2OH6dOeY0Y1lFxvrztqPzajJ29Iy7Wexw5lKUcLNwve32Vd/JNr816o4v/goDeyQ+M9Y0eHxd4o8Z6HomqeTpN/rt4Z7l4GTcGZfMdI3bjcqMQCuNzYzXdf8ABND4A3mlaRdfEi6sbWZrlZbDSTLO8c0Uf+rnniCxOSzEmFSMEEuMHcCOS+O/ww0X4v8Ax9bwt8OYWs/Deta9HFpKSXTXpsbXy2d2eZlVpfKQSMzhV3bCQoBAr9A/g74AtfDFlo9hoMbW1noIjjs+RuVIVURPnuQ3O5cliQc4NcecRjDG1oQSSU5JKL5opKT0jLS67OyutbG+BblQhKV78q3Vnt1XR910ZHpOqa/Bc3U40AxNZ3PlqVnjYQsrCKGIfKgZ1dVUYO0GNuh4FPWfHEXgXweZtS0m/wDmO/7RK1sWuG+bc5PnAjexk+RFxtK4yCAvplxplvJbR6PtuJLKxsXNvZIzeZcSSo/zbtwwiKrksxUnzkbhjubxP42QSeItRsWEcDR3MDXTnO5LO3M0jKGHCgqGAAAIywCnlRXk2R1nnHi3SLzxXcLPpfh/WIdMWOMRW7yQmRySwTdmVj8zMcZ/vHHu/QdA1rwybGS18N6teLJwiJHHK1wRgNwkhJJJJx1OTjNddpl7f6jqnl6W5h0vTI0vpFmVFa7kZHhVTzhgWaVVA4AUNwxOZdV8Y/YNAu9L3XkN5M6B7dCvluAGzu56/Mw29Bl89SAeTGcv4n8Za54nkjaLRdTgtY2S1RbSASRs5YRgBwxDM0jheDjccAdRWMviSYahZ280WpyQ2jPcGJSm1Hx5Y6MRzuPP+wOtdHZeN78Xtjt1K4W3s33QJnHkthvu8HDHe/UHmRj/ABEnC063gXXL7au7a6wIhHyqijPJHUh3dTj0xWnQzZ0VlPBqkJaDT9YYRrkfuAduOepbn8egzWlomuQ3rRxaZYXTSW4KHEJkaUjBY8Z6bsccfXrVO1e6lEcMXl2ixKHzvbKk4AYEYwRnOPbuMCvRPgv8NLXVr6GO6kXT5IU88X0oKRxPgkF/72ScYA789MVlzO9ka8qSuzhfEk0cL2MLWOreZJdjzlNm+BtSSUA+vzIp9cA1LDrNnag+fZ64se0sPLspm+UDOflGVx612fjfRLi18XaXbLdK0LR3d1I6jCF1MKEKFz0EjAex/CorjSW8JD7cqwyXB2nzZreK5ZMMGCjzAQoyq5243ZKtuHFLm7hY47xDdwJqFtI2na9HNIiOY5dLuFkRSAyttK52lSpB7jkcVetvErQWz7tL1ry12BpG0+aMxlo1lTllGMxvG+D/AAup7itjw54vm8KX76j5iTXV0yvJcXESzs5Eqy5JkDZPmRox9SuDkEgxar49k8VzPZPlvOlMqs8Yy7Ftx3MfmPJJ+YnGT0GaqyJuefaFNnwvprbb0Zs4fmNm+Q2xcY9skc+9SNcT3dzGZre/jkbaFYWbrvxgdcY9eeKveDLo2fh3TreUN9na1hLFgGKrtUEL6f4iug16OO1DQ+WkiybTGYM/JgAnryOpOD/e9qonqcvZ3CDWY0jttWaVpBErfZHILE4Axjv6GobTV1PiLVFmsNQa4aRLqRmt2Lcps598xMc/7XtWjfyyrOt07SW67ivTgMMYHTjHfGRn1rViitk+JFiL7P2e9st8rR4BYKYyuD2/1r849TjigoyZbyTU9Sigt9L12ZrmZLeMRabI6vISqKF2gg8uOBk9eODjY8HasljayyRWurlgE3qtqBGN0piX5i3G6RcA9yR0DBj111qWmaRc7bOQCw1ICG8KIFkl4+UM+NxUdNucYZhxuJPV67okWpeH7XTQLE2sjNPButIjbu5Ayz8BtzZK7hzkqTwgwtEG5z2lXbXkt1ZDw/qlzCSl4Cn2bciyYByWmDffSV8c43AYwRjnfG3jO7ttMubY6TqkcLFgd4t2jYFOuPOwGGAQef056Xx9qmqeCtYtdWjuWkuJJpIbhZsMB5zBssegZpViUE9S/eqd0Ljxp4X8yPT/ALLqF3PIka5wsrAICDzyDswM4A4OWywCA8K1K4u9GvZJjY6gtvbqXVcwcocbs/ve3Dcd19yadaXl5dx3cJ0rU2byzPvVoW2hPmLH976Z/HAHWtCXxFuspLW6WONcg4ddpTk/LzzjmofD13JHa/Z45HjkjV7ORlcr5icFQ2OvyhCRzyT9AMpdjuPhx8Xby8srLS7jQ5o9Ss8kNPcRwrcIVBI+UuSxDRuBg4bccfMxr54/4Km/s1389nZ/Eaz0uzh8qJINVa0uTMXhJCQzOPKQAoxWJjk8PCOilj3ev3+oWOuf2lb3bpeWMolTexdV4AHDE/LtVVI7quOgAr6E1Sz0/wCNfwZv7W4PnW91ZSWt3bhss0csW12XuuIzwfm5II2lWAqLs7oln4w0VtfETwTdfDfx1q2g3hVrjSbp7ZnUYWUKeHA9GGGHsaxa6DMKKKKACiiigAooooAKKKKAPob/AIJJ/wDKUf8AZ3/7KNoX/pfDX9juo/8AHjcf9c2/ka/ji/4JJ/8AKUf9nf8A7KNoX/pfDX9juo/8eNx/1zb+Rr2ss/hv1PLx3xr0PS/Dn/IDs/8Ar3j/APQRV6qPhz/kB2f/AF7x/wDoIq9XjS3PSjsgooopFBRRRQAUUUUAFFFFABWf4n/5Ba/9fNv/AOjkrQrP8T/8gtf+vm3/APRyVUfiRFT4H6H8SN0pfx3402jdjxLqGcdv3prU8IXVlpXi/SLrVrCTUtJtb6Ca+tFJVru3WRWliByMF0DLnIxnqK8z+J0Xh9/i34y/tSTUEuf7fvsCEDbt89sduuc/pWN9n8G/899X/If4VVb436hT+Beh9j+Cvix8CfDNhpMepfBnxD4gurOzjivbufxTPAdRm8pklk8lcxxZYo6AbwpVgQ25TE2X4ofAyz8SaffWnwl1+a0GlRi602412fyo9RDqHZZTK7TW7KJGAKxOPMSP70ZuZfjr7P4N/wCe+r/kP8KPs/g3/nvq/wCQ/wAKzLPqvU/H/wAKT4mt7zTPhvrFjp9v5bGxudYkvVutuo2MxR3ZlKk2cV9CzqMMbiMiNNpcV9T8c/DXUE0kr4I1C3vY4706vdxSusOoyyW1wlsYLQT7bVI5mgkZRJJnadpAXZL8ufZ/Bv8Az31f8h/hR9n8G/8APfV/yH+FAHqiwyBRlWzjnil8pv7rflXlX2fwb/z31f8AIf4UfZ/Bv/PfV/yH+FAHqvlN/db8q+jP+CWH7QPwj/Ze/a0h8WfHHwE3xG8CR6NeWbaN/YdnrG67kMXlS+RdukXyhZPmzuG7gcnHw99n8G/899X/ACH+FH2fwb/z31f8h/hQB+i/h7xV4D+Pf/BQz4oeMvh34aHhLwHrX2ibQNI/s2CwbSIWSAMBBAzRQ4IbIQkFJHHG44+rfBVxb2WpNLJAlnp1oJ7iad8fwwqpA7bQFkJ7AGIZJQtXzJ+w38NvEngX4L6Bp9vDocnhWbT/AO1hLBcCS9ElyVmHnlTgMBthIIBTKDsa+lLJ4NT0Bbr7HaxxXRSLbcsfKme6xM3m9isdsjSFcH5pIwMt1xk9Rkdqt1aaHZmOCW2uNcDzO8sgN5KHJZcrgAKvmKWJyQigbdoVa8r+I+i28Gupa3DLH89uQjMSJEEfy7/bKg4ySSqgfeJPvmveOW1e7/dwr9ntLV7ZmkiLTXBW7YfZpGHClnaYFj9yOFDnOGHk/wC04rnQ11K3VWu1ikmdMqGAQDDcYwAeB3HOOMEyWjzHX/HMOiyyXGmGOG81CUvDcIoDRRxkRK68YBd4i464UAqf3hxnW+i3fxB8VaneWq2dnLHFGZE5VRL5WDGgwcco5yeAByc4JyPEujSeH9I0+O43SSTQovmZzMyYBR+/3sEjB474JIptk6eEdJldrgR3t8Cvkh/3gjHGPlPAPzZ+n5gBfz2mh3TQ2+XYfLLdA8Kd2GK+oxkev9ef8LXkT6RbyLbq63H752ZivLsXIxnsWOPYdBVHXNXkvtPvMN5f7l9hx95mBCgY6fMeK2dBlkuGjjiaMKzgZYfKOcfgP04q7GZ2vh2ztb/Uo3a4Ito23gSnbvx65GPTpnpX0N8FfjFovwWuLa+XSbXxRerHgx3sUbWcTfvOfLdZBIw3fecYAHCg4YfM9pqAj1FgSv8Ao/JKEAnH+Qc+31rX0nxQsVsytG3UBcAnZjIIb8+1Qt7orRqzPRdQ1ax1nxlqTQxxaetvbRNHBFH5kMXmyzb0G7kZMScjniuf8SardfY5LXy7aExj7z/KOOuDwc+xBP1rndJ8T3T+KNQkhiw7xW0JVersoeQ4/wC/wI69MdOK7bVrCPXtHj3WzzXkK7nwoVwR0G0j5uOSOuc/irAmcS+l3wshHdRM1vMXEPQrIRjIU85xkEjPG6rNh4aujKqyR/vlYKS7FWTjBBJ49h34xU2r2rWaQ7rhWVnHlx3aiPb0ztkB+XGfYfUVY0VrqHV1W9kazknYuY5VEnnAn+9nDHuN3rkHJpj8iXS/hzDd/CzQ5LVmXUYbZYZlYhXzj5SDk55B9ODj3os7aPQ7TbqTTQ3EatGcgsCMZ3Y/vYyMe2al0LWLw+HT9oUxwrvYXO4LG6LI6YYrgAZ4z6gDvXUweAmi0eRVWCaGYLNIrD5lZgBleO2ckjg+nap5hnGDQG1az23yyNa3EDzWkzxFUeRDyoPchVOfQj3rC8XWwkk0O6X+G4NrJmPBH7qYEEf3SSh44PFdbo9l9ov1hE1xPbxQStBbEE+UxiIbbzjIPf2zUOt+Gll8JL9mWRnXUdPwzLhctLGpZieMY389MHnHagMa7jkFhMYFj3KBGgX5cjBzx9B171e8J/EXUvASRx3Ef2r5ggjnP+pCgbtp6+2PStqbwqzaulvP++hjkAmCscfe+9/QdeB61nnwHceKvGEqx+TawRx4gFwG8lvmyFZx0LMcZJAyeoHInoB1mm3MPxO8HTQ7rKG/vpAsUT7wqSrl4jkg5XeFZh8wxGSMEcdZ4gXT5fDcl3YLcQ6fqVsky2sj/aY498KsTHv+ZMxsoZdxIYdeQWo+BfDUfhTTpbGFoWuLcfabkjksSgJVc91IbIHXaMc4zydn4j8rSY4BeRrZmeSzt5mI3WiQM8cRBP3lCp0IxyfXJNgPn/4n6XeeFfE7ecv2jTdQmfbN5RH2Y4HD9Rg8cg4ye+RTtARtN8Waak+FWRhDKO4Knoffls/7ldr450O2N60epebeR3chULZboorbs2EyQWAxwMeoBORXHaz4YayvLWS1ne6uLcIxJ6GMJjJbABby95yP9nqSaYFDXrPydakB+aNhsKkcnPb9a7P4JeK7i20TULW1LR3WmkyLMz/61WAwNvXCFDkjtIQeMY5nxrpWreGp7wXVheW13pUjRTpIm1oijHO76MMA+uB14rL8JeKV8OXUM0g823vC9vdqybXh3BgV7cb9p9MfU00tCXueIf8ABUP4TQ+H/H+heMrC3MNl4stP33B4nQA8npwrCMYxn7Ox718tV99ftH6dD8Qv2aPHOi3k0bXXh+SPWtNaV8KskJKS4PffD5vAHLFOnNfAtbQegnuFFFFUIKKKKACiiigAooooA+hv+CSf/KUf9nf/ALKNoX/pfDX9juo/8eNx/wBc2/ka/ji/4JJ/8pR/2d/+yjaF/wCl8Nf2O6j/AMeNx/1zb+Rr2ss/hv1PLx3xr0PS/Dn/ACA7P/r3j/8AQRV6qPhz/kB2f/XvH/6CKvV40tz0o7IKKKKRQUUUUAFFFFABRRRQAVn+J/8AkFr/ANfNv/6OStCs/wAT/wDILX/r5t//AEclVH4kRU+B+h/B78c/+S1+MP8AsN3v/pQ9crXVfHP/AJLX4w/7Dd7/AOlD1ytVW+N+o6fwr0QUUUVmUFFFFABRRRQAV0Hwn8FN8Svil4b8OqzK2vapbafuH8Pmyqmfw3Zrn690/wCCbPhyPxJ+2l4LWaPzILGW4vn4+6YbaV0P/fYSgD9UPE/hHR/F888j6TpszSIYYHktY8xCEAJ8+NwUMVIC8gKOxxXQTfCbS/CWr/Y1muNGt9Oga+me01W4tfscqIzJtEcgVWKK4ViCF2rxgjMXhbdpsun6gtuLyO3QTyQv/wAtpAztgDOfmZo09ASx4AzWjp9vdXeueIoY4/tE1hcaXpsk2/8AdyyT2zSlyemEbORg/KVJ7k4XZSRlWfhiNPDtmtjea9a2NrBEJIZdZuHjjuJEjJXdKx5ASZW/vCFBgkFa4j9qHw3cWmm+YdW164iku4oBGBbSmUKRI658ndwoII4Gc5BwRXuEejteaK3krNZ2capNNGg3bnKfIcLk+ZulfrnhueMYp/E7wNceIdK0vSo4f7HuLOSa6mSWPbMnlobeSAqThWJlYjuvl4PJNIPI+QfiH8Orzw1q7L/b01+0o3BvLgZJXIXhAIvur90nuU24AXnmf7Bu5tSZrm/mmmBHzNFG2OwHAAC4PQdh26V9JeMPhZGb9WRI44WQRTyXLGSQKhKK+wdMt6/XgdPCfHitD4guA0ccW2dwixIyxn5iPlB6AY6HpQUcr4rs7yC1tA11Z5muYjtWz67XD8kPzwh6e/PFZslzqhu2khu7TaQcxi0YL6ngSds5/X3roNeZmvdPg2qk32lnzjadvlSLj82FMj0RjJNvgkkjUHykjB3O/UZPYAAsfXbjvmqUiZFTTtS1Y2hZrjTVkCjIFk+4DrnPm/8A1q6rwx/bF9p4Zb6w3EHDSWcm4jHI/wBdzxk/5xWJFcuumLHJEqTE+Wdg6jB/UY/DHQ1taddjS5FlZQZMFQu84Tgjt83bgjjrRYkt6C2sWfiPUGN1prXBvVAzYSPjFvAQQPO6c+/f1xXpHhm518QrcQ3Wi/vvlKmwlPIHf9/+PtmvO/AOsXWp6/qU88Elwhuh86DLKRGkZPoR8nfrxXtnwj8GT+I9QWzkh8+3k5SZX4RlyRg44OTjB7flUy1Kjocj8XdL1DUUguo7rSdQVYAlzKmmzKqS8Eqp888AnAxjPoM1keFdBvNO8PW102pW0dzNIfL099LldLkAjgt569cAYx346V7nL4FbTtOuLVl2DUI28sHaWkAPAPHOMfgcHIrx99Dvv+EsaWJWMMMxCO82Fi3MQu45PfkZwTzSTvoD0O6+D3hzXNT8ASTNb6BDdNc3X2ZbjSJWkMi3MucMbrbnlhjbgeucmtY6N4q0a6tvO1Lw+unwxE7Ros2HiJx5ZUXBwygg5GMbB1Ga0PgPrlvaeEVs7y7hhudP1C7VSsm6JmW7lLcE8Z3Zzz2r1DW76LWZoYobKMbFIZ2lZjPuycjPbBxj2FLqFzy5vhN4qtryFY7zwz9kmEg3vpUikvyEPy3O7JBAYdO/PWsD4i+FvEmj/DbXFkvvD7LFp8s5WHSpwwaJSwKs1z1DAckcY6EV9TfDv4O3FxDNFMwMdpAtxdv5qq67lLRDcwYMAFB5wAXxyckePfG/w7dQ6X4j0uZlvI2s7iOK4iT/AF2+IgNngfh17VRPkeafEPwn4i019Ph/tHR1jZ5Vuns9FkZoWK7kdla6y4DfL3xnkHqOBu18WaXGkj6po9sUcuPJ0sp1PT/XHAOAdv3enpx7RcXEeqeHo9Q2SKtxb+elyqhiFcBiGzz6DHt78+VeP72HTIPJkkN2sh3fKeBk9eCc/wD1qCo7mFe/Fi60/U4IW1y1hdSkgK2Kwsvzn5Gyx3EJjnn06DA5G+0y6udf1dZNdmhtjcLKEEUI2740YlVCkBSS5AGOQaj1T4c33j7xjDEuIfsIVlEit8+WA5xzgAduma7ab4OtqWqanJcSfY5l0+0ZfLQMHJefJX6ZT16j6UFHB6Xcvpeuq0mranIqybhGI7b5vcBoiCR1xXUePfBy+MfFWlNput6pHpkyMptpo7dJ4wNzKQ8cKcHG3IGSeO5xwHjfwHrcdoPs+6aSzlCSuo4ZS3DKfUYPI9wfb0j4MeC5PEmtf8TCOMrLZeZK5fHktGikYX0K5HHcL+II4H4xazcJov8Ap2pXk2sXNuPtey6ZcvuKkOqYw6sAeeufTNeWzWb+IBcPcPdXEzQqiiW5lk8soqqnDN2CAc9MCvWP2i9NaOwkuLiDyb6zu5LaVFff5y7nddx4+YBucdCAMY6eZ6BqVxZR3V2YxJHNH5L5HKnnB9uR+laR2IIvAusaToHjGJdRs7WTT7yGaxuWWJf3sUi7ck4zyBg98Gvirx14XfwR431jRZJBNJo99NZNIBgOY5GQn8dua+vbeCEywqQjqGKPk8DJYc/UYr5y/aytI7P9oPxEIV2pK8E/1MkEbk/iWJ/GqW+gHnVFFFUAUUUUAFFFFABRRRQB9Df8Ek/+Uo/7O/8A2UbQv/S+Gv7HdR/48bj/AK5t/I1/HF/wST/5Sj/s7/8AZRtC/wDS+Gv7HdR/48bj/rm38jXtZZ/DfqeXjvjXoel+HP8AkB2f/XvH/wCgir1UfDn/ACA7P/r3j/8AQRV6vGluelHZBRRRSKCiiigAooooAKKKKACs/wAT/wDILX/r5t//AEclaFZ/if8A5Ba/9fNv/wCjkqo/EiKnwP0P4Pfjn/yWvxh/2G73/wBKHrla6r45/wDJa/GH/Ybvf/Sh65WqrfG/UdP4V6IKKKKzKCiiigAooooAK+qv+CP2if2v+1Dq0n8Vj4Xvpl9tzwxE/gJDXyrX1h/wR41KfSf2kPEk1vZzXzf8Ipco8UMiJJsa6tASu8qpxnkbhxnGSMFS2A/WbxD4NfQNNjsiqbbu3kDKw4ZZ9+xx3+WNZQR3YLwea53wh8OLXwZ4jmVrWWO4uLy1ht0ikUJEkNtCW4AzuKSzyM2cuYypxuNTXnxz0/XNf09dWXUNPW1EZmlvrZraJoxGVXDuAAAXIz0BQHOCpan4E8ZWHiM4XXNLvptPe7lT7PeJMFlMrqW2hssSPLyynhYhyoOTgET1L4bQ2sMawXEiWdhql/Iru4+fAimJcMx4OYVVFB6bjk8Vk6742bxT8Rf7VktmlubPSZIGC5uXZ7ieHMkjdyXhkZcAsTKzfxYXP0bVZvDniS1a6iLLbRyyxpKGyJHtXRWQrgA+YN+cbQy8rjFWvBXh1dF1zXVgMsNpDolmimMfKswlncEZ6oGYjOerdck0XKs7mTqvhe71nUZbOaR41MrKsdu/l+e8imTc7DnyvnU4+9jaOmBXzp8WPh5qUFl5N5c3TRw3b5mjiVxE6yNFKWXglgUYBQ2Pl44Oa+w9E02z1O+1GCRpJPtCxW/nRLny5TNITKMjB2kKTu4AI6mvn/4+TQ+G9Jt4la3eGOS4hnVF2bzHPJGsicY52Nn+8yk9c0rjR4abbw1ofj/Q7WS+k1SG4truW4nut628Z3ReWFCxpK5ABUlgCfMGBlTun8aR6KmqXVxpmpQTSWssUMVqkTotwxQmaYblGIlwiKCxdmDMQoIFcV4/tEg8R6XIkjPFsuGZS2Sfmt+B1IBGPaobW4a3LM0chjZcgg/cAOeD9M/nTJOi8uOIF1jeORn/AHhjfYuCD0GD6fzqO6sY9QWPy7iby0wsivsGeePz/wA4qPRp2vtHYb23xtu9hjI5B74OP85q1Jqkdno32eK1RrosS0kjDL5GMAe3P4/QU1cRs/CKz02zlvI/O1HMl1O0ZhGZAUldQOuBwM5/oM19K/CrXdPm0SW3ae4WaMrxcld+ckDPfqMH1A49/kHwrrUmm2SyAt/o95cuU+6CftEmVP16fiPSvbNM8R3sfhSz1CxZlvEQO0qRbUBI3NGB/EQH7A43DpSloB9M6lfabpnh0XRmceUmR5a8McfMPbOPX868Mbwr/wAJdqt49jq+k6XZxoZDPevktJ5c0hQR+aHILLGAwXGSQDkEiTXviJcWXwos7dprJpppCEWLb9oMRZid+OVIbIHqBg44rF8J3K2kMElwQZlk3LC5wrjqAT6A5464/A0RA0vhb4B1jU7e8nTUtHsdDsr/AFNIbh4YXmuwr3DrJ5fmhlLsvl7RnBUDcQ4I9S8JSXGmeELK41LUrWC6msftMtvABI1iS7KscjKSA5VVYjJx5gXGQTXiPw38X6lpojgt5FaL7deyBin3P9MnyOefU8+v5+qW/jHU7bwHqMkZtZ765jCIjAMN2V2gd9xxx0x3oA0r/wAY6pYQx3Ed1Ju2soCqySLbHJKuM4IP+1lc56cmuL8QfEaPRfDl1dXUlw/mSEOyEt82RkegJJ6Cugv9Kfxj4ZfUpvOt7i8BiRdoGNpK7SmSRnO7GScnAJrz/wCJljd/2KzN51q1y+y5t5o8Dy2OQMd8E/ePTigDn/hZ8SvO8F6ZIupNeNdadbhYiB8mI13DGByOQQMkH8a85+OHxPj0/wAXfYTaywvbsuCJyFPGQxAABPJBz0AHfmul+E9np8nhDw+trHJ9pj06J4xJME2yiMMd2Rx3PXn37Y3jrwpb+K9Vh1CFZFvoZPLO6QN5RdcHJAzgYPXpk/hStfUDvv2eLiTXdUt49SuJA0bED5j1U8KR2PQZIwABW9r8Rk1myGn6u8N1f6FfG4unhDwwgrbGONFEe44lJGT0M2cYXD+d6ANT0XXrOBhGsMi4LBdpK/xSA56bSPp+HPZ+EvGs0fjG0eNftLPp940rsmciSazGcAHkbVxnoeKkDv8Axh8IoW8MnUtDgkFjNO2wt80lyFYDe2MAFyWcgDAYYwBiqugfC3+x7ePULiOCzmMLRz/ZwQnRVzzyAD5Yy3BLL2YV6Bp+gf8ACReHbWzhkUJeB1tQ0p4kIGOSfXjrgZJOBmukSOGfw/p811DI06wb55Cd6z5aIlCSMHa8e8g/88jgkEigbdz5C/aV0D+2dI15vK/fGaCUjIJTFrCvB9NyEHrnP+8a+fJ2jtYbeBIvM3MglXdhZNpJx9CcA/j9B9efFLwXHZ+LPElm1utxarYWpgkuGYIjt5gMu76qByMfe4IAr5P1jRodL1fUvmYQRxyPDJINioq7WbJ6fKWxkHBPTNaR2EZ2p6xNr+llbiG1hW3mlugIkKbSecDnGFUqoGM4QdeTXyb+11b+R8d9U/2re0/S2iX/ANlzX2n4N8IR+Ovhz4jlgh1C4fTZrcxSWtrLJDhkdpN7hSi5UKQWYDCn3r4x/bBlll+Oeo+dC1vJHFHE0buGZNo24JXIzx2Jpx3A8voooqwCiiigAooooAKKKKAPob/gkn/ylH/Z3/7KNoX/AKXw1/Y7qP8Ax43H/XNv5Gv44v8Agkn/AMpR/wBnf/so2hf+l8Nf2O6j/wAeNx/1zb+Rr2ss/hv1PLx3xr0PS/Dn/IDs/wDr3j/9BFXqo+HP+QHZ/wDXvH/6CKvV40tz0o7IKKKKRQUUUUAFFFFABRRRQAVn+J/+QWv/AF82/wD6OStCs/xP/wAgtf8Ar5t//RyVUfiRFT4H6H8Hvxz/AOS1+MP+w3e/+lD1ytdV8c/+S1+MP+w3e/8ApQ9crVVvjfqOn8K9EFFFFZlBRRRQAUUUUAFfUH/BJHW10j9qS8jJK/2h4fu7cY9nikP6Rmvl+va/+CdviGPw9+2V4JaZtsN/cy6cRnAdp4JIkB/4G6UpbAftj4dxpumrMszRzeakJjUcqVbv9FZsHsahn8M2Mnh50vrKwvIxqFw8iXEImBjaS6QAlgQwLpHxjggHsM2dFimu9Ndo1VrhoAQGXh3KlsYHrsI/Disu117VNJnubDVtHkGnzXVncy3UE3mR2glQTlMhcEx7yxfpjpnHOA0cdefCrQ4pYdPXRdFt7jTyxnkitY4RtOcxq6gblUjIcnO3A6E1Mup6PoPxCTS3t/FG3UNMs0d7bWL+CCFEN1I25VlGCrgEAkAOc4PNdj4p05oNQ1JZ1E8a6ldRw3Ecf/H3aeWjpgDAbDyuucEsIxj5sk1rbS7rVviU1rqMM0VvdaYEvZS+9ZoISCdjZ6+XcqpPGSR3OKWpZveMPhPovhWwmuy/iKz1KGBYoHm1ee5NuJCwdws28xyASDocYHIBwR4h8VPhg0xs4pLfWLPTzFFI88P2ea4vLcRxgBC8HyEskjrjAPmgHIUGr/7Y/wAdNY0f4rrp99LJDDNbl8K+4Ts5O9mOPvAgAjHVcV1Xg2bXPiJ8DrfWJrNYbfT40hjvi2RGibgCWbIyRvY542xdOGpa2A+OfFHhDUdH8WW9rfXWsWtytpLPEl3bwrvVngIIHl8qwOcnrj3rNuoprCIR295cSRswGJoYm5HHZRzz+ten/HLw3H4r8d6bImrMs1vay2k88zn5WEtuNr55+Qvs9c4XaCpFeazyKZJI45FdckjY2Q2D94dsYzg1ROpb0OPUFZoVvuGDEr9j3dsnow6AHPsM0547+Ap/pljICfkBs3yM88/vR2xXQeB9Yj329kIbXy5I5IJZmO0yAjJLHOflwOO4yO9RzaPcar4jkt7WOcyxtht3yENjnPOOxGTj6dqaDlOXgudUi02+WaawZUurh9j2bblJuH7edkAde+Nwz1zXbeC769u9Bt/7WvvJtYba8Ns9nZmOf7W0Y8oszSMNgYDPy/xZ5xtPK+HdJ+1Br1ZGnaO7u1eN4jyfNmPf1ByfTB611EN/J4gjWytV+1raokaNCH2puYsc5A2kk4PGPr1pt9heZ13h3xPBq66vNfatcWVw73AsYLa1aTbG0L+UrO7kvtk8oEnGQScLghq+rXesQanBcL/ZLQTOfKghs5isWSfL+b7QWO3CjJ5bvnrXI+HraR51zIpMbcDqHOP/AK2P8ivQNJ1WfwzqtjJ/rJF8swo+dh5J/LOePepEVfCPirxPp+mzW15eaPG1vd6gqpLpUm9JftkgcHE42jf69Oepya3rKXxDpkMMn9raIttcTBxv0mVsbcBOPtJ+UgnPJxjvVH4eHVNK8P6pqEdvFNHrWp3aPArgFR9skYHb12BiBnpzzUeurfGK9t5lNrNaSrIqxlJIwpYKVDdRyc7R6EUX1LR1V/8AEvW1tLC4t9a0nzLKcIiDRZRkEtgj/SuScKce+O3O18QLjXviHZyTXGt6W5vgqMYdGlUrj5R1uTj7oHpxj3PG+CvDMWqeEZLlrm4tbi1nRdp2tGxwfmABzn5c4I7k9Ovp1no1tbrp8cnnXFu7rG5TAfZn5s5456Z6cfhUti5Twnwl8OtaXwPod1HqVn5c+l28uILZDIEMYPzDcQDhepAx9DXYeBfhXDfQTahqF5ffaFmQRSGBI1VfLkWXK/dZwXRlDIwyozkKBUfw78ZxaH4M0QyR/aLdbC1t5NyECNGgQnOM5PDAficDgD6a8JWuh3fhGzi0/T7OFjEZ2MiAElcbcD73zEHkjAyvHJxRJ4tcfCRbfwhEtprWttJ5EsH2ySOF/NQeWy4R43CsdmDt28dB8zZ4fwz8FdQ8O/E6GK+1bV5IY7G7MZhe3CzKktt3WPBUgg/9844r6ecfatIWweExWOnuZ98SbzIflDDjkk7AMD2PfNef3l5o9v4gs2uL6xWySyuyx+0x7YudOcoSpK78MSyg8L6ii+pZr6N4At73S7dYr7xLG24JMYtZngBO1SNoideSY3YgDG0jvnE3iH4fWL63daZK2tXSwxpH5ba9fTq8h+UsoeZs5XaAMdzxg4O14ftbjUobcqk0dx9uBSI7laOMhkUEY6EODnvtB5AOZtZ0GbTdSlWWRYs3TvDLs27RHuUPnHRMkBehOD2BADPJvEnww8MyeJ7iP/hH9Ju8WcEjiW0S4kfJv1jCl8nDOtvGwJyBJux1K8P+0B8GbXwNo2owJBY2t9Gn2WSK1RUjjiikOR8uMr5mOvfb6YH0B8GdA/tX4ly3F2YYW0SVNMmjZgyyMIUljUdPlEssxOOu4HcOK8K/aFdvEmpGK2uRJDa3UtkmWCo8cbOFckkfN90MxIB244wMGpBwPw7sn0j4VtBJvgF/NdJOrZBKOFjHfjAibk46Y57fmv8AtdXTXH7QniJWbcYZUjyDnny1J/Umv1M8OaC1z4Flt7q4imP2a8nhWKPaxhWbG8Dk7izFsZwFHf5iPyT+OGqnWvi/4kuDz/p8sec5zsbZn/x2tIbgcrRRRWgBRRRQAUUUUAFFFFAH0N/wST/5Sj/s7/8AZRtC/wDS+Gv7HdR/48bj/rm38jX8cX/BJP8A5Sj/ALO//ZRtC/8AS+Gv7HdR/wCPG4/65t/I17WWfw36nl47416Hpfhz/kB2f/XvH/6CKvVR8Of8gOz/AOveP/0EVerxpbnpR2QUUUUigooooAKKKKACiiigArP8T/8AILX/AK+bf/0claFZ/if/AJBa/wDXzb/+jkqo/EiKnwP0P4Pfjn/yWvxh/wBhu9/9KHrla6r45/8AJa/GH/Ybvf8A0oeuVqq3xv1HT+FeiCiiisygooooAKKKKACtj4feLpvAHj3Q9et8m40XUIL+MDu0UiyD9VrHooA/ot+HkyeMZ/tlrcLBZ6mseoidMGOe3Z1kCo3O0EZGQNyquR1qJdM/4QDxS0Gs3FnqWl+ILJYIjFEdvmxO8D7zkgHy2BJOARbqoAbAf5l/4JbfG/UvH37LPhaS11KzvLjRrd9JuLG/gMiGayw0USyIyFd9uITlxIQTgYAFek6t451zX7S+uIbcyLK/kWsun30c5QG3jVZCsqxfM0sUO8jJO2QHJYMcdQO40K9uptW1DS7eFmfSLhDEtynzThDIvlqc8rtZlA5+WJjnn5ZvFWsNq/jjQYluhHDNZXr23GPLkZoGCMuOcrEwx2MbenPG6t4ottbgh1bydY0vWt62s7/2bdFbdovlZRN5ZjJjLKylWIwU5OTus+MPjD4WlbQNYOt6GsdrfW808LX8S3FvHcK8RZAT83lPNvIAIIXGRkB4dzQ0Piv8MNJ8ef2Y+taba3U1lIbUTBCJIomLtuG0jOWypG75S6ZBK89hZfY/CPwZ1DwvY2v7tkmnjillIQrkgcLhCfnRRgBv3ec/M1ZunatJavptjvh1nTZLqUjUba9idQiRKd74OJE8yUqf4gFU8biTc8Qarq2i3em3lxbwrbtO1zHF9jZcqUYAgE4ddkrdCpHlkYbdlVqgPJ/iNo9rJ4q8MW5tbRtH8P2t75Frl0tVWZmlc7Q25d7owbndhFUEgDHkHxW1ma7vLqzvDp8Md49uFkjVm2RwIyxxYLY25kkc/wB+Ric4Jr6pHw8k+I2o+Hr6xt7axtZL2MT5coYc2F7sQEnhjKUjA24YyREMpDg+S/HH4KNq2pyX2no10vRxt/eOAOMD0PQAjJ9jnBcD5zPh68stVkW2jklC/vN0IJWPIz1A7jPt169a2nSbxVdq1zcJHdXTqnnF1VS4GFBPRRjAOcdc17H4b8IL4W8Bk31vNaXwlK3DswRo7fgs+BztXZuAVhkswIxgnhLLw7YjU7iOG4F7pmpTN5LtGRvi3HZJkE7c8ZBPBPtRzAeeaVbNpi3Mc6svl3k+QhG1nyW5PQjDdvWuh8PWpjnht/Lt2RtqmESiMy9cdfYnnnGfWtaD4Twxtq6/bZPtOm35ESzxF43R7e3cghckHLk9D1HIxXonhz4TafrPgq6mVWs9StAktvK0Jla4kAX92oxlVZlzk8AE9utCPK7jVFGsXN40jW8BuGZYnZpGJLFsdOcbvz5713vgVtDe2kk1PS4dW1WdSsX21I/s1spSSJGwyFmZTIWxuwcKMAKS3nlxpkkemvuuLfzoZiXjbBP/AHznj0+v6XpNbkt7iH/RY7NFwrpEzHdhsdzn9T0z3pa30GfQHhubw5ong/VPEVzoq3GoW95qauboxNZieWe4gTbD5WDt3lwgbA3PgYfFeH69rh1W60uzhs1sY7OxEDS+aHe/kEkjNPJ8oXcd+0ADCqigdKsQeIrtvhncabaXH+iyXlxcSQy7VkCJcSMCp5wxBwfU9c4FZ8Hh281rVoP7Jtbm5jlUmEMpMi/3uAB3BOBnAIyTgmnqJaHTaX4oj0+1gWSGSSGzlaVmDEZJYkAjA5wSOvb2r1TQtWs9V8MXmoXGpR2sC2s00SKm52ZIi2zqcZbjJGBzzxmvETZ3AiaMozTSSmMKM7iRjOBnk/MPzrorma68JeF9Qtr5GM1xpNzDbxvJkYMbhScEjILKcAdCeeKmwzE8T6veW+oaPbSQLZx2VpF5qByfkEaLyOxBGD/kn1v4QfEm81qfyQq72VICyj5RnGeMjgKHbPoMcdRyf7Qd5pun+MrpIbaG9tdjWqt5mwhwWC529SvytjPIAzxybHw78T2PhLSoZL9JRDbObm2XyciUkBcbsenQk926ZNUSew6prd3B4e02WOVVs9QAnJHUx9ABjDDdgZYgHAwMgk1iQahpUmrTrqNrYro/hbRI3is5oy1uvmtKshC8kErCpLZ3EjPUAi1pPiNvFWlebtj8qO3EjGWNnBklAYBTkBQqsBnGST0UKN2LqemR654t8UR3TSQwWhgsUjETMkv2cJcuny5KgtcrGWOTjGRnKiYlHd+C/HsWqXN5qHlXsLzuZpPtI8qUliCX25JGSSccYLnPatfWvFl14o1VZpJreHyUC7N29bVfbGQCTuweTjGOdtcff6vHoGnvZtcR2ck0sdzfXkkhijWU5/djOP4WbI7E9OMVUvfiP4Z0i5+ynWPDczqdvmS6nG0MG5tzSMFbcwRfl2g5JAzjmqQHV+C/D0ml+GG1qZo1bULuS/dUkHmRiyleIuRwAALZW546Z6gV538R/B9r/wAIXfXyiOKaeJ9TfJy0cc88zxrg/wB9iMnGQNuM7ga1NN+JFnqtlpcIj1e8J2z3Bh0e6Me6QmaSPd5ezJlY7gTglmB4rjf2oPF+oWtjssdDk02LasTG+uoonvnZmYybYfNygTzAA5UgswGAiAMzPK5/FsnhvRfFFvNcR+TpWnOqSDGzZsZGLH/ZSRjg55B7Dj8kL28k1G9muJm3Szu0jse7E5Jr7/8A2r/HL/D79lHXJrq8ka+8VXDafbxwxiJW3EhyzZLkbDOBgqpMeGB6V+fdaU9hvsFFFFWIKKKKACiiigAooooA+hv+CSf/AClH/Z3/AOyjaF/6Xw1/Y7qP/Hjcf9c2/ka/ji/4JJ/8pR/2d/8Aso2hf+l8Nf2O6j/x43H/AFzb+Rr2ss/hv1PLx3xr0PS/Dn/IDs/+veP/ANBFXqo+HP8AkB2f/XvH/wCgir1eNLc9KOyCiiikUFFFFABRRRQAUUUUAFZ/if8A5Ba/9fNv/wCjkrQrP8T/APILX/r5t/8A0clVH4kRU+B+h/B78c/+S1+MP+w3e/8ApQ9crXVfHP8A5LX4w/7Dd7/6UPXK1Vb436jp/CvRBRRRWZQUUUUAFFFFABRRRQB9rf8ABF/48f8ACG/FfWvBdxcLEuvW51LTGcnal5bo5ZQB3eIsx/64KOhNfX3jI3nwtv7zSYplhtbi5ebTnlBVoIZg2znBUtGdh+oU981+Qfw88d6j8L/Hej+ItJl8nUtEu4r22Y5270YMAw4ypxgjuCR3r9o9MvNK/bF/Zk0TVvD8iL5lmLm2WWTPlIyZkjLKM7450aJ8DAIGM7VIzlpqB6H8Nf3GiWcy2rf2Lqt1HbzeUh/0S9KxYdsHKRyLPCrEcLKhOcScS6vp2oan8O9RjmEq6hptm7RBWyJgwR4ZRxjcZUww/vLKORg1lfBSw1a2+FeqWHiCe4t7/Rr+3vJthDI7W/mrJKNrANuw4HIHyjOQxz6N4gSTSfsM0N3BNIytHdNbybUmUupVgScnCyM3HOBIcEgg5lROPtLXQ/GCwzQ6Pp923kCWWefTomWeF8HPK5BUuuMglgpAzgCs/wALfBjS73xM9hdaH4fs9BS3jS1u/wCyka4hfa33ioUgH5OuDllPVhntPhLq2i6V4oFvqdjb30Wmy3EEsMEvlytZvGzwZQfNlUNodwAw8fctXefCjwt/wmt14kt9OuoZRPDCLmMIZHuV3EAOjYORkg9GJOeoqbDueHeIfhhb6Dp19qFrJq1j/Z95aXj/AGbWLiFQkdzE00iiOb5trBwwC7lOOnU1te8ALaXs1ura1arKrMQms352BmV2GWlYbQzN1U5Cg8nOfbdT+CNx4og8SaLcW81nPf25tbW4S1NwbmKaIB5kHRpNzDglj+7Gcg88ZJZ3esaJp+rRaKqvcxQXsluqsohVgHfKkAgKXX05xzzRqF7nj/xh8Bw3baTY2eq6x9oeR1juZL6aRYAMARs7EqpbGApGSWPXg1maV4B1OzsrS2sdW1SNfNVAIzAHUHIyoMJwMKpIBGDwegNek3EX2q+vd62dxGqfv4FiET7lweUOOnTDYB4IPrc8M3kej+JPtk2mMtnPIwtrieZZjINm8LIMgqWjQlX+YMcBhllBlMo8v0X4d3keva5pv/CSapaut1FLkwWucG2twMlbdictHtGOBx7k9DY6X4i012VtQ8UeTJbRzHyk05vM+U462+BnevJGScg44NSfGn4n6fpHjbXLvRoYYLW/0LToJbOZkuAjl7sSEBuSowOnQkZzwK8Yu/2g/FfheGO20+9tJY3ieIyvDiXbIu1gzdWwC3PfPfpVCNbQrGPxZ8QL+z1S+1i48iN/KFrHZNPIoPyY/cBW+Zh/tdMAYrj9O+FV54me++0eIbrRfsILyQXXkRy7cNt+URfeXgEe/rxWaPEmrHxIt9MxaeYAJIkjxs5A2hldSB8oxjPAwPrXrXwU8GaL4ltrjUJpEvr/AEtgyyXJDqpONwkTex+8SQ+Wz0Ixgk2FueZ/s/8Ah6TXri302XWtREV40iGLybZXcGRzuG+IgY5Y85+uK+h7bTJvCvhjUGvfEmtQ3lhbNbQx+Tpq+aqx7RsC27HIXknORuUmuW+Gl3ayabYQ3lvYm3S1E0d1Im6R1dy+0NwVU5P3cdQckHNamqWEXinxPZx3moLa2t+RbQs7BI2I2qN8gBI4B5wfugc4qhHmOmR6ppdqg/4SDVrlZ5RMsK/ZSwAzjP7n73JHPbHGMVT8d6DfW95NHLrV48klxFZyh5oJGSOWRYiPljG07XPTGDznNdV4m0ZPC+u3SrPHcRxsYVmhIKO2MfKcDjjGeufcVwPxG1CcXkVosawrd36ylhkglA0oz+MYA/E9aBlzxF4da2e31SO91K4kgYFU+1SbsnB3fLjocce4rtPhT4ZvfixC9usOs/ZbdFtzK+rXfkxxgnOB5n3/AJiR2yegrjbNYfDdmLXTY7p5rraIJJ3GQckbzjpjjHv+v0f8C9Nbwd4JFrcLLZS2qZZ9+VCPncdpGCTyeR0AoEVPDvw2hS/t9Pjh1i/mkAuvJXUZ2W3t1lPklw8wU4EcgVfmZsyk7Rgl3gP4OeE/EV/fWs2kaW19/a163kS26ztKLaZ0Ks7KdpKJGcnGe3JAbtfFOuXHgbSr3VrC0uLW8hsjKN8SRzSRoGf7odlDMWYDPIB781w+jaU3h3w6bW6uVZYdKNnd6hLbCUAGOIN5ZYgMzblJJDZMwXd1Bko09O8L+HvA+qX12ugaStxPdTfZp4NOigBQExLsUKWO4ouOpJkXgADE/wAWvEUPilLjTLVm0u11CZLeKzilLXBid0V2L+vlszDaOCCedpzHFcr4l1qa4NxHGkJVY1B4tm2japH8JCHeAQucjgDINCWX+z9atI5G23ek2Md1cskgdreQqyrnbgFwhuSVGQhlAG4PuJF3EW9aTyre3gjMaXV0ySX1x5uI1j3gFFPUbMyAleT5ikcgE+f/ALSt4/jnXrew09VtQbdWsoCoUAbnVS3QAKiEEsernHyg12uhQXmrS6hNK0VtDBFbLmT5/JQMzHHp90g4HJQdSQp8j+O/xO0v4eeEvEHii+8630m1si8oLASPAqrHHEo7PMzwr/vSZ4HWhdT8+f8Agoz8Rvt/jHQvBtvIGt/DFp51wwP+suLg+Zkj02FWHf8AeEV831r+PvGt58RvGuqa9qBX7Zq1091KEGEQsc7VHZVGAB2AArIrdaKxIUUUUwCiiigAooooAKKKKAPob/gkn/ylH/Z3/wCyjaF/6Xw1/Y7qP/Hjcf8AXNv5Gv44v+CSf/KUf9nf/so2hf8ApfDX9juo/wDHjcf9c2/ka9rLP4b9Ty8d8a9D0vw5/wAgOz/694//AEEVeqj4c/5Adn/17x/+gir1eNLc9KOyCiiikUFFFFABRRRQAUUUUAFZ/if/AJBa/wDXzb/+jkrQrP8AE/8AyC1/6+bf/wBHJVR+JEVPgfofwe/HP/ktfjD/ALDd7/6UPXK11Xxz/wCS1+MP+w3e/wDpQ9crVVvjfqOn8K9EFFFFZlBRRRQAUUUUAFFFFABX2R/wSn/a2uvhzrOpfDu6uLiO318PcaJPHMEa0vgvMYJI4kVeFycsu0IzS4r43qaw1CfSr+G6tZpbe6tpFlhlicpJE6nKspHIIIBBHQ0PXQD94vhF8R7pr1obj7PHfQxSfa44TvjNu2wPIEwHRlZggDj5W3EbuDXpWowR6eynytun6mzQpDHiSOEPj5Fwo+VVLchRwB8q7hXxT+xJ+1bY/tSfDu3OrfZZta0oLDrdhcRLLG7bSouY0IICvjJAAwQw5ABP0rp2hafdaTPpd1NqFum0hHg1G4jgA3LsljVJVjDKSxKgfeG5eDkYMo1b/wAPXml6zaxyXS293vCQu58xTJbuZ42iYDq0ck+9C2B5QG478t6X4G8c6Z4f8RSahqDLcSQsqS3UJWz2wF2ZTuB25GZMZXG0jOMZryLVfCGtak8sMPiCT+14JTNaS3sEM9u7r+8i3ABJPnKjcC4A3cfIcDGv0vtTtdL1a+XSI9N3SRmNba4ggtJSMGC4xKzSxo5dfkO0ZkO75VIQ+h903+s6HP4JksZpG1JFUyW4nuCbryzlZrdmkZfMQEI+JHYDeV5RUrwXwZJbwJqlrJceTeWl1Mg81U80I5+2RSbMspxHdxxsyYVgig425PmWk2/ibw/Pe6barYO19MqPFc63PNbxxmRXKLCLfkEh0ZS3zRlVBGASxtRl0bxk2o6T4PsY49aWRWW1vYHjs5IN7uIvN8mQu0ckhyUJAgHBjDFRkRjY9I1u3i8SeXJY2toqtKwdoNxkI2/KVYsRt3cFTwAXwdwAPK+K9MPgmeGz1izvJPD/ABG1wYnf7GxcAoApBGVbA4YEgAK2Plv/AA8+IHijQL64jg0u81aSNBcebDd6e19PuOwq6tOionEWHwGLMylmO3bv+Nru718313Z+F/FlvpOqAXMiywws1hLJzGxZZwyHzMZ+YDLgZPBqeUo+W/jn4X0+f4n2cdndvNJqOnz7DIkgW5WOWPYUdsMeJGOGCtjGeted654Zj0q3iRo3mumnDxlnGxo8cggHgnHqOPzHunxt8NWepTaJNqul+JLO6s55Ejd9NkZXf7HJKRtVmIVjFGSFLADkFgd1ea+OtBj13VtNutPh1jRbeeMpNFcabclWYKGTayoW+cEHnHBJycBSK5S1PM20+UPNJHIwaMqGdTtdS3GAM5Ppx2r0D4Y65qHhvQLTTZofJhjnZnLOUV92AGBxwQQM9QQMY4q0/gPT7zWLWSzutRj09wscd3daDerJcOzJu/cIjuoC+a2CWysXBJIU+heHoNN8JeH521a6vmgs5UR/M0S9WSWHZGTtQRECN5d4VA2/bkkArud7gcSvhrVNG+E+l3aWfl2V9bRSR3QcssiiJRsznG0Y6lRksACc4G7o95bat4Nhmh8xLzSZkl/eKCrjjjrj72eDjIbJ6HHMeFNf1Dxx8L9Jaz0vXpNO0mxiVJGspjaW0wjUl93kMUY4wCG6YzxnPefB7SrE65Pb3Ca5eJqNn5KJb6XdmNZH28MfKAbHY8DuQO7IPN/iBM1oixs6wrIMxuh/1gYA5I9CR+H4VyuveL77xJf2VhNsFtpcFxNHtTJR/wB0hbceclXOfevZfG3wX1IYW80PWYYdPnAMjJHG/lOcxttZ9y87hkjg9a5mH4dXU3iq6tbfwPrV6vlwRIQ0DbT88rjcJkx+7aEnd2PoQaBpnIeGYZItV0+RcPJCd6/L/qx1Vicex6dxX0d8ENCke0fUJ5LiZJI5JVtVUA3UiAFQGPGTnbyD0PXoU8F/AW71HUx5fhvxDCt4jD7HaHT0EsUcihWlm8x3SF/nDFVZnGwIdzbl9Ff4PePxa3Nnpf8AZ8guEMdvbh1tjpVsWLSN5ixtubywF8xnjC4ZucgKC6nKyeCNS8Qtp9pqUz3M+r3sUj2waNInWNvtErjd8wi3RrCWJKgShfvOA2p4v0qHUdX0ycva32noftzyWcSMk7bVjRY1GdxZimzLNgoCzqBurV8O60viK/vtM0vRfC13Zx2J0qSUX139muVLF7kwN9kVZIyRGpcSA5t3GdoJOV4w1jxlf2cd7qWpeG11a5tomks49Gk2WMXGLcTfadpYZJJ8sfMMEDcRSaKTNrx19h8O6TG12q28VnGZBbBkfyiEj3eZtG0M0jKuMs8jnCBQoI8z0rUodTjka6uBYzao7Xdw7qSrCPZsRsZOEiSIyH1UHkqSIfEHh7UvENzaWP8Ab91Is0g86SCzt4LVIVKltu6JzyWUAGTcEkXkcsYvF2laXaeZZyaheOscO6+uHu5XaU7fNYuFfZtA/h2DdmRgpGFZiKXiH4m20GkWmmQpeRW19bLKIfs7i5vIhgrIUx5nzrJGq4XALJyxya/OP/gqV+1DP8QPHH/CC2LN/Z+jzJdajJjH2i42Hy4wOqpEsjccHdIQwHlqB9JftgftUaX+zJ4GmvtPtIIvEets6aTpwAVYjggzTDncsYc5yTudygOFLJ+Xur6tda/qt1fX1xNdXl7K89xPKxaSaRiWZmJ5JJJJPqa0guoivRRRWggooooAKKKKACiiigAooooA+hv+CSf/AClH/Z3/AOyjaF/6Xw1/Y7qP/Hjcf9c2/ka/ji/4JJ/8pR/2d/8Aso2hf+l8Nf2O6j/x43H/AFzb+Rr2ss/hv1PLx3xr0PS/Dn/IDs/+veP/ANBFXqo+HP8AkB2f/XvH/wCgir1eNLc9KOyCiiikUFFFFABRRRQAUUUUAFZ/if8A5Ba/9fNv/wCjkrQrP8T/APILX/r5t/8A0clVH4kRU+B+h/B78c/+S1+MP+w3e/8ApQ9crXVfHP8A5LX4w/7Dd7/6UPXK1Vb436jp/CvRBRRRWZQUUUUAFFFFABRRRQAUUUUAdb8EfjNrXwE+I1j4k0OZo7q0bbLEWxHdREjfE/qpwPoQCOQK/V/4B/tG2fxz8CWfifw1qixFYJITZyqD9muMAGKTkFSBnAzg5RgcZL/jnXf/ALO37ROufs3+OBq2kt9otbgCO/sJHKw3sYOcHH3XXJKvglSTwVLK0yjcaP210TVIde0jddKmoWbSF5IrUOjW5DZDoud6hhwyqQY5FyCoZVjr+GLmLwRrs1nqTf2ppXiCNpbO5EzmVGXG5RkFZNykMY2Vdx+YNukjz4n+zb+1Lofxl0FfEWhzXHmW5UXSonmyWrsAMTRLyvQgkja+CVLYyfY9J1bS9d097O3vY/s7zpObWGZJUhc72Bj3k46sUI+ZDjG5NwrEs3b/AFW+0nRbO7XTLXUNHsU8pwky3FxBGCQHEedrqFZTgYUjrlhiqt9rNnc+IoLTSWxr0fk3cFlaCSWe++dkaOFcfM8iGRFVwdhdeflBp2iwxGwmt9QjljlRWjm/ciRkbGd5MgPmKQGIZskrgHGzednwrpNv4bukuNHuJ7HUld1aK3iCRyK4ZtwjADDKyNhRnAZvmJbaJ9QMDwfdx6XFHa2Hiex8Q28N2YIjELeO4jkkQoyARrv80yHbskHzJIoBAOa9M0b4g+JrC4t7KwRtS+zjbBGvDwD/AFjEnIKkkklG68k4IFeW65Pp9lbalZ3X2ZYYDDevFPYNcRSqhdoCyyK2fJdplUKGwfmxmQk4ngjWrHxhp1tY6XrC2M1qvlWlpbs0cjqoK7BuVmePkE5jBdDgrxmhha52vx58WX8XhNb6a3XTbm31K3ltxbw5hQGTZLgtuXb5Tylifm5Of4q5iw17T/FKyQtqTWvAVoRHI7yjlmZt+9QM8kqQeG7EZ1dT8Lf282qWU19HDPqVrLbmKWaRTCjp5bhN3yhQGBJGRktzkMapeG/B9hdXFnq9mtws11bCfZFJkxGRQ68kkLgEjLHDDv3pPYCHR9Lj8O63DdQyP9nVHifzbbzCHJJyudpRiCy7cN37ZK5nj3wHrXieSO/0vTb7UNPvoUy1qzqtuVZmO/qrcNlQSdpyRgMQPStH8PtqWiXludN0+5aCMi9guN1kCMfLIyH5/lXqVVSD8vA642vaElsNW1C30+PS9R0+0N95d5G0k3y7GR1X97EQrQqFYLlH+bKtsC2hM8k+Enwym1Dwbo1lbx/aNWjs7U3Edzc/Z5IUMSMrqrriRRzwrEjbyOgX1nwH4ct/BujyatfSK14kyItwpyUl4yU52uwXGcnIDYKn7rZWj/DrTxZabp+teF9C1i3mhhW/ks5ZN0zKS5EqH5CuTgqE8vaoyWX5a9YsNAmt9Utb6axtvDNuZBJDJcSp5jsC2MnzArEFi20DGWcAjdQQdJZXmneM/D+l3TTaTpuqXQaKUzzCNXCgnzHWQ4O1lTJIC4diVY5Uc18KvBtxq99chdRktLhri7vGmtNOSeK+CTeRG4/dlfLFvDARjYWd2zjtszWV1p3w18TX2o6pol3NkxeTeHdFaagrAWjTTHZER50qllaNWXzBwduD1GgLFpHw3sYLFLn+y4YYUbU4jcu7QQrtxsYEtlkSMPgIwDAxRZAoAveGPBH2DVZ1msZMz3f2sh4HtVKRqScCRVYqEJb5AeZsbmZzU37Qvxy0nw18Ob7SEGntfafCLmXT4LSSVkQlmRbx0Vo0814XQecRub5V3AYbPK29pfSaNDqFn4bjNos99cTzwDU7wk5WPMrlFkZU3liA2HQhvmYji/GviH+0PGcMMm7XrXQraRoDZ6nbyO9zPAqxKZFijCAKxjMSgtL5+ArCMkAGLp/jbTb3QLfT9Nkkm066gEr3d1G0F9rsz5HntDI6hLckeYzOH8wtlVByay/GVvpdvoKzam04jmU7oIJCsixLGwK5wTubcDuHZFUrya2PHviPVPCHh/ULi/uvLnunMq2FkYreKe5ccAjYZpz8wy7yY3PksG+UeS654y0nz3huNetb68lnDmMPE8duUJJYkKSzBlChQ20YVym5kCAFt73U23TW8a2M14q7rXT1Q29sCcrCG5dtmWJO4BnJOVB2L4l+1B8Z7H4JfC7UPEWrX7SWenOYbHT7eQQfbr1mZhGJPmdsldzsDldh6hcHS/aS/aZ0f4MeCZ9e1ibULXSOYLYMdl3qk4GfKiRiG7jL4wMZJ6Bfyu/aJ/aO8Q/tKeNRq2tyLDbWqmHTtPh4t9OhznYg7k8FmPLEDoAoFRjcp9jG+L3xe1z44+OrvxD4guhcX1zhERF2w2sQ+5DEn8KLngdSSSSWJJ5miitiQooooAKKKKACiiigAooooAKKKKAPob/gkn/ylH/Z3/7KNoX/AKXw1/Y7qP8Ax43H/XNv5Gv44v8Agkn/AMpR/wBnf/so2hf+l8Nf2O6j/wAeNx/1zb+Rr2ss/hv1PLx3xr0PS/Dn/IDs/wDr3j/9BFXq+V/G/wC3PZfCbx9ceGdWk8RQtZz2VhbtZ29rdS3clxayXK+VbKpnaNI4ZAXCtlkZQDtYivc/8FC9NtbBbwjx01h5Qd7lNLs2WJzFBKsbYPBdJiUb7kgj3ozxzW8k2P8AZVaWqtr6/wCRt9epxVmn+H+Z9YUV8teMf27F8J+M9S0COw+Iuqalpd09nMINDgt4XkBwhjmuBHFIkjAqrI5y20Y+YGotT/b9s9F8XTaRdQfECN2isrixnGi2/k6lFcrYlWjJAwyNfxo8b7ZFaKX5ceWZEsprPt+P+Q/r0Oz/AA/zPqqivksf8FHdDbQv7SWTx89qsjW8siaJbskEy2txc+U0g/dk7LWYb1ZowQuXCsGr2LRfHmqa/o1nfQatfrDfQR3MYkt4FcK6hhuHl8HB5HY0PKay3t+P+Qvr9Ps/w/zPUqK82/4SbWP+gxd/9+YP/jdH/CTax/0GLv8A78wf/G6X9l1e6/H/ACD69Ds/w/zPSaK82/4SbWP+gxd/9+YP/jdH/CTax/0GLv8A78wf/G6P7Lq91+P+QfXodn+H+Z6TWf4n/wCQWv8A182//o5K4ceJdYJ/5DF1/wB+YP8A43UXgrxvdeM0keS71CSCG5jiMdzbxxHzEniDfdUH5SSvXGVYc4zRLLasFztqy9f8iXjqcv3et3f+tz+Hr45/8lr8Yf8AYbvf/Sh65Wuq+Of/ACWvxh/2G73/ANKHrla4a3xv1O6n8K9EFFFFZlBRRRQAUUUUAFFFFABRRRQAUUUUAdR8IPjF4g+Bfjm18Q+G75rO/twUdWXfDdRHG6GVDw8bYGVPoCMEAj9JP2af23PDf7S+m21vb+XpviS3Uibw7eSq2R1Z7Jm4lTjc0fDjbyrbd7/lnUtlezabeQ3FvNJb3Fu4kiljYq8bA5DKRyCDyCOlTKNwP290e6s3TMH2rT1DbhBaX9xa25GT8ojVgI+SSMKdpHKtnA65PCF1JbtNa6peq1vw6vPEkjDqrIZkdHI5BVirBhgkrmvzF/Zw/wCCpWteChDpvjy1l8QWPC/2pAFF+gAxmUHCz8YGco55LNJ92vvD4G/tF+H/AIq6BJf+F9fstUsX2+dE38D9kljb5kbHA4B9AVFYyi1uaXO6160nvVSSbVJr5oYmjeNoI2MkD7fMEYQKC21QwHdo1BJBxUFn8HTpGiLdadqHh/Ure42lFktj5zJgFXb96oxnGGUkdCDSyIt4w8hzbNcASqryiRpOpygO0k8HJXbwD1xmmeH9KS0nkiurqS3td5MShdo81zyu4LuBJIIB+Uc5YLjEANF1rtppljDrEmjtqgGZd1nLGHXcdvziRwx6AsAGznPOcZnw11G906/voVXTZBDdyEE6k0eRKfOABMTgKPNK8A4MeMdq1dW8PTappplVVDx79k0cXkplScAhhnGMEjpk4AABB4iayl0PxtGUsrm3ivENtdKS4YyAs8e5lIGSC65ABJZPQUAepLq1/qNuv9qaTY3Ol27KsLXF488EOQCQyJApwwB2lVz1PQ0fErS7i98D30kOiwyaPb6ZcORPr7XVmsqwsrMqSoQXAwCA/QHauQax7FF0+3ttSs9SWPao32s2FaNc/MrsIwsozjhSHPyk4IIrQ8W61c6p4UvfOtLNGktTZxTNiK4k8w+UmI1mfbgsoEbeYCct8pxtsDqrDWfE2n6kt1Y6bHHa2pBuXvNXkmt0Axk4eFUjGAeNzAYB6qALfhbWrPWtaZG1Pwjq2t3SGEXAuJ7+WRAu5oYo4YkUIuTx5qjJJJPJalo+mQ6pfwrq1u1xaySCTymu4o3kcHKlFdQSSegJ2ggN16dReeNPDttp0en2ekbZ5H3y3N/ci6kjA4IjiiQZGMgsoIOSFYnighlrxFZ6tqniXTbdtS8Lq+gqly63OhzSmyfBSGMstyYFdpJJWGGYk26EFmZQL/iTVNU1Gyh0rWZfCOluv7y5TR9MludWveAQt0RPcOgLKm5BkMARzgha/g/xTa6Np0+2/vbG9lmIJS3kt1tUwVjiVWQqu2NgWG44dmCt82TlS/E23+Hdq0Oh6VNNeSMwghmuUESyMxJZoljjIwcbmcBc8FW3qKBFvWjdaFoU0Wna9Hp95qTfZ/K0yysbeItjdgtJarOscSvufOw5O05eTB5rVdHj0Jo4V1rV7ia33xeb9ulj/tB2kBlVGtTCo+6DM4kKIr4xuzijfeNG0RdQ1C5uI9e1q+5vNQuLmS4G1Sf3caTKyoBufGHAUYxks5fwn4//ALWHhn4U6OuoeLdZa1hugYoYNkjS3hQkhVUHJVdxPyjaN4ztyRT1A6zxZomn67eSQqJpreM8mVGuhMB9/LSu2xdpAPOCPmyRlR8//taftzeHf2btPm0q1mt9c8YRxqIdLtmC29kSuQZmjwI0GciMfORjGxWDj5r/AGj/APgqp4n+IQm0vwLA/hHR2Gz7awVtUnHOCHGVgI4wY8upXIkGSK+U7q6kvbmSaaSSaaZi7u7FmdjySSeSSe9XGn3K5ux0Xxa+MPiL44eMJtc8TalNqV9INkYY4itox0jiQfKiDJ+VQOSSckknmaKK0JCiiigAooooAKKKKACiiigAooooAKKKKAPob/gkn/ylH/Z3/wCyjaF/6Xw1/Y7qP/Hjcf8AXNv5Gv44v+CSf/KUf9nf/so2hf8ApfDX9juo/wDHjcf9c2/ka9rLP4b9Ty8d8a9D8cfgv/wdleNf2hL9tN+H/wCxL478eX1myK9v4e8Y3OqSws6SFcpBo7lSyRSkcchH7KcVPhj/AMHikPxN1i4tYf2bJbRra3NwXf4llsjcoxxpX+1mvyV/4Jxf8FVPiF/wTD1zXrzwNoPgDxFH4jubO7vbXxVpMl/CZLWK9iiKeXLE6fLfTE4bkhPTBwf+CfHwl1X4ufE7XLPSZrCCey0n7QzXUjIu0TxLxtRucsOCMVx06laUuVNnVOnTjHmaP3o8Uf8ABxx4y8DeErLXdW/ZW1TT9E1BgkF7J8QG8lmOflJGlnaxweGweCO1cj+zf/wc/fET9r74ja/4T+F/7G+qeMdZ8N2kuoahBa/FSGDyLWOZYWmJm01BtDyIDzkbs9MmvmT4i2/j74ofBW/8J6ha+GYr/U5LQzXkGrXKwypb+UE3Q+R1URKBz3JO418LfsK/8FCdW/4JXftV/EvXrXwtpvjC61izvfDE9vPfPaxQ/wCnxTGVWVCW5t8AEDhs9sVy5fWx03JY792lKyemq5Yu9lKVvebS1u0k2k3ZduaU8vVOlVy28nKnGUoSd3CTbTg58lNSskneK5dbJytd/qN8Q/8Ag8fvPhV4/wBc8M+IP2Vb3Tdf8NahcaVqVq/xQV2tbmCVopYyy6WVJWRGGVJBxwSOa6S8/wCDq3x1afDTVPGj/sTeLpPCOheQdV1qLx5JNY6V57rHB9plXSSsBld1VBIVLscDJr8M/Fd9qn7bf7W3iXVrO30/RdU+JPiLUdaW3mndreya4lmumj8wKWIXJUHbk4HAzX3R8T/iN8fvF/7HXib4R6lD8JrnQfEuk6LoE1+73p1DTrPTb6K5torUpGkagyj940ySuynhlIBr2MNHno1Jub5lblXfXW+nbzXz2PHrS9nUhFxVnv5drfP1Psr4T/8AB3lrPx18b23hvwj+yHquv61dJJMlra/EnJSKNDJLNIx0oLHFHGrO8jlURVZmIAJqP4qf8Hf+pfBH4har4U8VfsmXmj+IdDm+z31lL8Tkd7d8BsEppZU8EHIJHNfjP+yD+13rH7FnjrxNqOm6PpeuL4m0S58Mapb3Us0PmWczoZVjliZZIn3RxusiEMrRp1Xej8f+0F8btT/aK+L+seMdXj8i81ZolEAvLm7W2iihSGGJZbmSWZlSKNFBd2OFA4AAHDGrWfNKU7apJa3atdu+y10tvpfrpo4y9soKHuWvzed1ZWvfa7vtsu5+32qf8Hi19ofhyz1i+/ZE16z0nUv+PS+n8fyR2111/wBXI2kBW6HoT0PpVn4Wf8HgGqfG74jaL4R8I/si6t4i8TeIrtLHTdNsviP5k95M5wqqP7K/Ek4AAJJABNfibf8A7TWpzfBFPAln4d8E6XYNtF3qNroy/wBp6gBj/WzuWOSyqxZQrZGAQMg+r/8ABN3wX8RvA3j7Tfi78P5PBjah4av5rK3j12W7XbKIo2dh9nAYApMFyHGQXBBB50p1Ks5qKk/6+Y63LTpufKrrZd+2ttD9ZPjF/wAHc/iD9nzx/eeFfHH7HeveFfEmnhWudO1L4htBcRBlDKSraT0IIII4NaGk/wDB2p4un+FE3j61/Y51yTwjbyBX1T/hY2YQElXLAf2VuMYkXYZACgbKkgjA/LT/AIKdeFPiF+0l+0JH8TvFEHgzR5/F13pPhe3sNKvbqeOB0tBBE7NLEGIIt2Zm5OX6Hk16v4Zb9obwl+xDq3wHttW+Hf8AwiurL5E05kn+0GHMny5+z5ziV1zkAgISpZQ1elg6EKkqkcVOSSTtbq76X36a207XW55WYYrEU6dKWEhGTclzXvZRt7zWq2dlfVpaqMtj5R1Lxv8ABX4ofEGeaP4W/FybVfEWos6QQ/ErTgHmnlJCLnQu7NgZNTfEjwz8K/g74ok0TxZ8Ffjx4Z1iEbns9U8fWVrMFyQG2voAJU4OGHB7GvP9Kmf9m748sNX0XRPFVx4R1GSKaxuLu+gs7mWMlQwltZra5Xa2HVkkQ7lXORkHov2x/wBrzXP2yfiZaa/q9pFp1vpNhHpmnWa3El1JBApLEy3EpMs8jOzu0jkkluwry70+STnfnvpored+q8rX+R60vb+1jyW9nZ31d76Wstmu92rdLnsvgP8AYj034nfs2at8XtB/Zz+POo/DnRfPNxq6fEvSVEq26lrmSCFtEE1xHAoZpZIUdIlRy5UIxHmnw30j4P8Axe+Inh/wn4b+Evxi1bxF4p1K20jSrGL4maYsl7d3EqxQxKW0MKC8jqoJIGTyRXuX7Mf/AAXN8Y/sx/sMzfBvT/Bmh6leWOl6ho2g6/cXkoXSre9nuLh5JLTBSe4hlu7poZN6KpmxIkyqBXyj+zH8bLr9mj9pH4efEeysYNUvPh74l03xLBZTyGOK8ksrqO4WJmHKqxiCkjkA1zRlJt6aLbbXT0+R1cttb3+/Tyf56dHbe57p8ZP2YPBX7NP7QGnfDT4nfA745+A/FOoSWn+i6j8RNNZlhuXCxzrt0TbImd3KtjKMuQQQPYL7/gm98CdOG6aH4qRqWCBm8W2GMk4GT/ZXHPc8V51+3Z/wUr17/grX/wAFCfh/8R9c8L6P4Q1C3XSPDiWVhdS3ELJFfSSLIWcbgSbgggDGFHvX2za/CbWNM8UNfR3OlyRsmyS2nDyIWGdrggDBGTkHIOBx1z+ecbcS4jLK1GFGryKSbfuxd7Nd4ux+q+G/C+VZrGtLM4tqLSTUpLV73s+13tq0ldJ3Xwd+0F8Afgt8DviTovhiz8DfF7xNfa9arcW4g8e6fbuXaV4xGF/sV8n5M5yOvTjJ4rx/4V+FPwrv47fxF8G/jdpEkxIjNx8RdPEcpAUsEcaFtYruUMFJKk4ODxX0p+0f8GPGUn7avgXWvC914fj1rwTpNrr0P2+aUQsyX82z7sbZIZQcEYx69Kxf+CjOqfHf9pn4VaVdeP8AV/Asnhf4ZnUdT06z09XF1E9/LHLd5k+zoZA8wLqrEBA5A9/v+F6kMdw/Tx9ad60n2STjrd25Ur3SW6/wvdfl/E0J4HiCpgKUEqMV3balpZX5m7Wbez9Vs/I/hJ8A/Bvx802S68D/ALPv7Qfi+OO4NoE0fx5ZXk0swUO0UcUegmSRwjByqKxC5YgAEjk7KL4N6j4uh8PwfCL42S67cXg06PTl+Idj9qe5L+WIBH/YO7zC527cZ3cYzX11/wAE9PGXxw/Yy+Eljb+E7X4Va5pepazbeNILPxBLezWst19mjSH7TDFGpkEaZZVWRcSENltor538K/AH4i6D+3Jb6lb3HgmTxlo91F8QQk0t0dLkZb9JBEcIJSDKQCuQdmfnzzRSpY/mqe0ppK/uba6aX1f6enV9OMllcaVF4WrKUnG9RO/uu/TRdP8AF3vq0nfG/wDZp8P/ALM1pb3PxG/Zn/ac8CWl5O1rbXOv+K4dOt7mUDcUjkl8PKjsF5wpJxzXnP8AwlfwF/6Jr8Xv/Dlad/8AKKvtT/gqR+0Z+0J+298DrHT/AIkR/Cu20fwhdz+IY30W71iW7keO2kDjN5LKg3IT8qBFLKuAozn81R0rSjTxEI8uKS5vJafjdnlUa8asFJJrur3t89Lnq3/CV/AX/omvxe/8OXp3/wAoqP8AhK/gL/0TX4vf+HL07/5RV5TRWv8AWyNP66nq3/CV/AX/AKJr8Xv/AA5enf8Ayio/4Sv4C/8ARNfi9/4crTv/AJRV5TRR/WyD+t2esf8ACT/Af/omvxd/8OXp3/yirS8JfFr4O+Adci1PQ/BPxt0fUYciO5svilYwTID1AZdDBwe4714qOOlORuen60W/qyDU+6PBX/BXbwn4Z0c2OofDHxz4gj8xZBLeeOtOjlYjBG7ytDRWwQpyVySOSa6C5/4LQ+AL64uJZvgj4waS6Tynb/hZMIJXt00jt+XHSvz5oqeWPb8ETzP+mz9HNC/4LseGfDZZY/hL46lhYbVim+I1pIiJ/d2nRMEZ5BIJHrUOtf8ABcLwdrdo0bfBnxhbsuPKeH4hWR8vHIwJNEYcHBGAMEe5r86VYrTozgVXs49vwQcz/ps/RCD/AILceDrdpmX4R/EAGYEMB8S7TamSxJQf2JiP738AUfKKzF/4LL+EYRbxx/C34imG3mSdVn+JVncFSjbgFEmiFAM8/dJHOMZNfARlxR5mTj3xR7OPb8F/kHM/6bP0il/4L1aBPE0U3wk8ZXELtljJ8QrNZAoGAilNFUKv0XPPUcYbp/8AwXf8I6bpv2OH4M+MobbIZ0h+IlnD5hH3SSuiBuOoOc7gG6gGvzdFGKXLHt+CDmf9Nn6O6x/wXN8DX2jtp9r8D/GGn2czBp/K+JUBuJlGcJ5x0fzFQZztVgCQv91cZumf8FrfAejTNJa/BfxxC8n+uK/FBF8/qAGA0naQqkhQRgZJwTzX56UUuVdvy/yDmf8ATZ92eN/+CwXhXxPoy2en/DHxx4fIPFzaeOdNkuIx/sGXQ3VT/tbS4wuGAAr538UfFP4N+Ntbn1PWfA/xs1bUro7prq8+KVjPNKfVnbQiT+JrxnfTWbfVcqXT8v8AIpXPWP8AhKPgN/0TX4u/+HK0/wD+UVH/AAlPwG/6Jr8Xf/Dlad/8oq8nxRii39WQHq//AAlfwF/6Jt8Xf/Dlaf8A/KGk/wCEr+Av/RNfi9/4cvTv/lFXlNFH9bIP63PVv+Er+Av/AETX4vf+HL07/wCUVH/CV/AX/omvxe/8OXp3/wAoq8poo/rZB/XU9W/4Sv4C/wDRNfi9/wCHL07/AOUVH/CV/AX/AKJr8Xv/AA5enf8Ayirymij+tkH9dT1b/hK/gL/0TX4vf+HL07/5RUf8JX8Bf+ia/F7/AMOXp3/yirymij+tkH9dT1b/AISv4C/9E1+L3/hy9O/+UVH/AAlfwF/6Jr8Xv/Dlad/8oq8poo/rZB/W7PVv+Er+Av8A0TX4vf8Ahy9O/wDlFV7w9N8F/F181rpPwl+NmqXKoZTDZ/EOxnkCDq21dBJwMjJ6c144jbHVvlypyMgMPxB4P0Nd/wCG/wBpzxd4f8ZX2uTXsWrXWraaNG1KO8Q+Vqlj50cptZxGUMkX7qOMKx+WNERdqxxhJ9PyRS/rc6rSovgnqPjSz0Gb4Y/F7TdQuryOxK3nxIsIfs8juEHmD+wNygEgngkDtXeeM/2cfhn4A+G9z4o1T4bfES3sbVLeVof+FtaWbmRJ47SRGRP7C/eAfbIg2wnaVfOAAT4npnxQ8P6hoXiBvFPheHX/ABFqYgh0/UEuHs4tKhjt5IPkggMcbFQYGVWBXMCg/LvWTp7P4qfBe3bVGk+Gd5I19Ghs0OpXWNLkGGOCLkGZSxZTu2kxhADG+6Qmv9W/yK5T0r9iD4ieAfCH7WXgLxJ8NfgL8cvHnjPwbrFv4k0/RLDxxbajJeGycXLBobfQTKYwsZLlcbVBORjNfqP4/wD+DvDXPhl4z1Dwv4u/ZF8Q+E/EFjCZLvTNY8dSWN7bK0Hnpvhl0hXXfEyuuQMq6tyCDX42/s7/ALY2s/sc/tZf8LS+FlnZ6O1ldXi2GnahH9shXT7lXie0cuS5DW8jRlw3mDOQ+4Bql/ar/afk/a8+N1x411BbmbXtQ0oQ6ne3EMcUl7JBpcVqGKoSOfs5fGfl83YPlQE1GtUhpF2RnKjCT979T//Z)